Smart Cat Feeder – Part 4

This is the Part 4 and final blog of the series where I detail my journey in learning to build an IoT solution.
Please have a read of my previous blogs to get the full context leading up to this point before continuing.
- Part 1: I talked about setting up a Seeed AWS IoT Button
- Part 2: I talked about publishing events to an Adruino Micro-controller from AWS
- Part 3: I talked about my experience of using a 3D Printer for the first time to print a Cat Feeder
Why am I building this Feeder?
I've always wanted to dip my toes into building IoT solutions beyond doing what a typical tutorial teaches in only turning on LEDs - I wanted to build something that would used everyday. Plus, I often forget to feed the cats while I am away from home (for the day), so it would be nice to come home to a non-grumpy cat by feeding them remotely any time and from any where in the world using the internet.
What was used to build this Feeder?
- A 3D Printer using PLA as the filament material.
- An Arduino based micro-controller - in this case a Seeed Studio XIAO ESP32C3
- A couple of motors and controllers
- AWS Services
- Seeed AWS IoT Button
- Some code
- and some cat food
So how does it work and how is it put together?
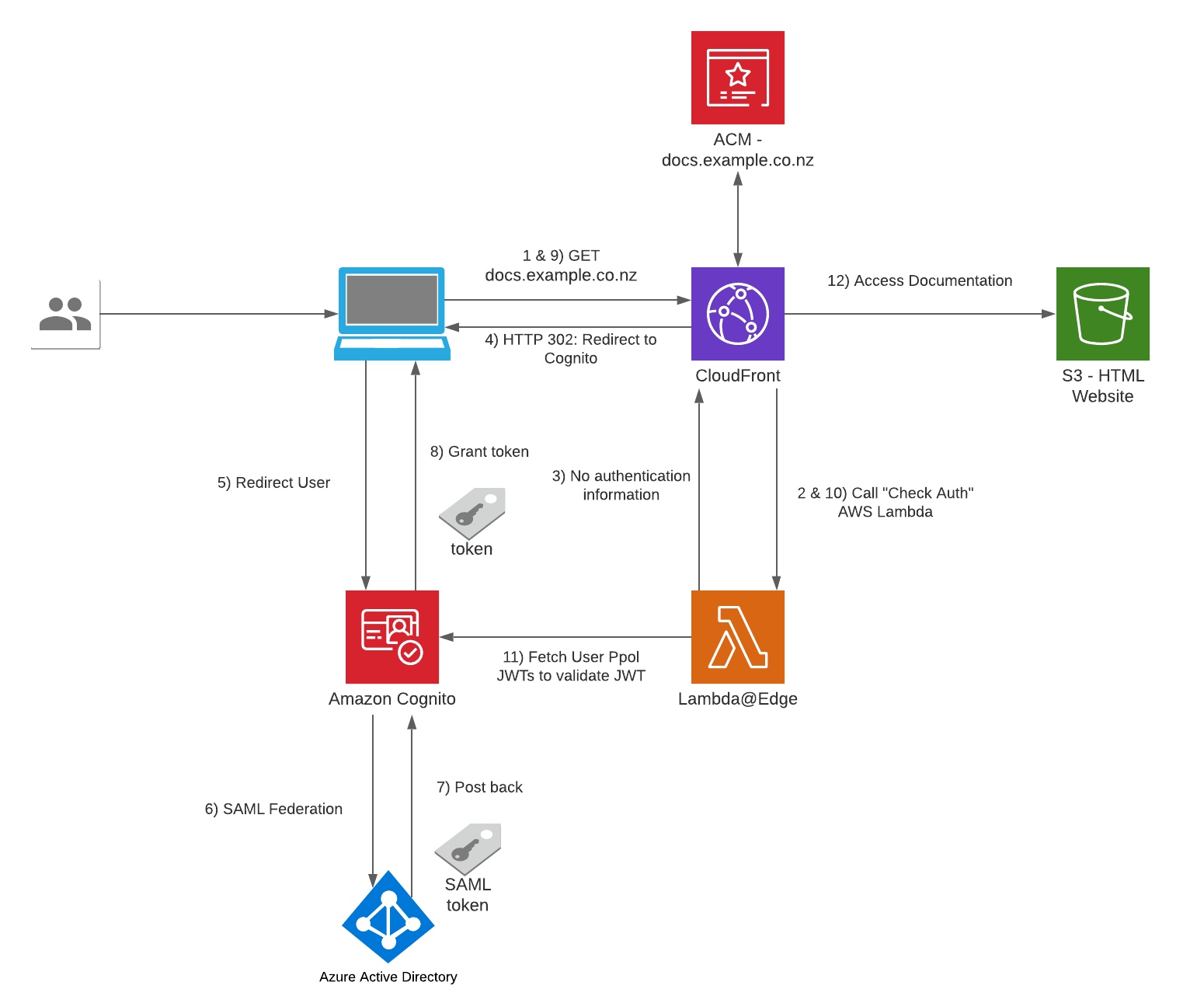
To simply describe what is built, the Feeder uses an Iot button click to trigger events over the internet to instruct the feeder to dispense food into one or both food bowls.

Here are some diagrams describing the architecture of the solution - the technical things that happens in-between the IoT button and the Cat Feeder.
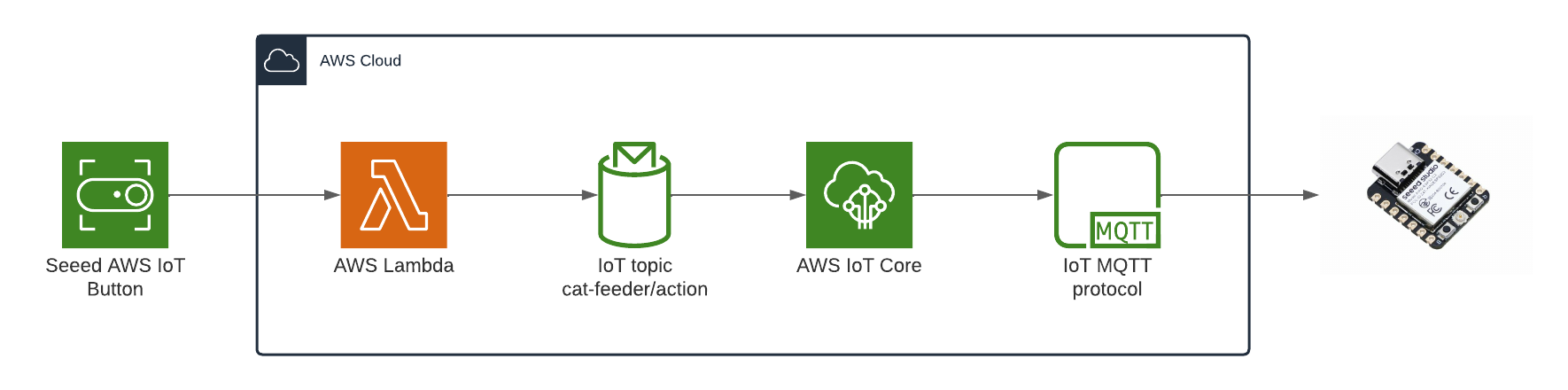
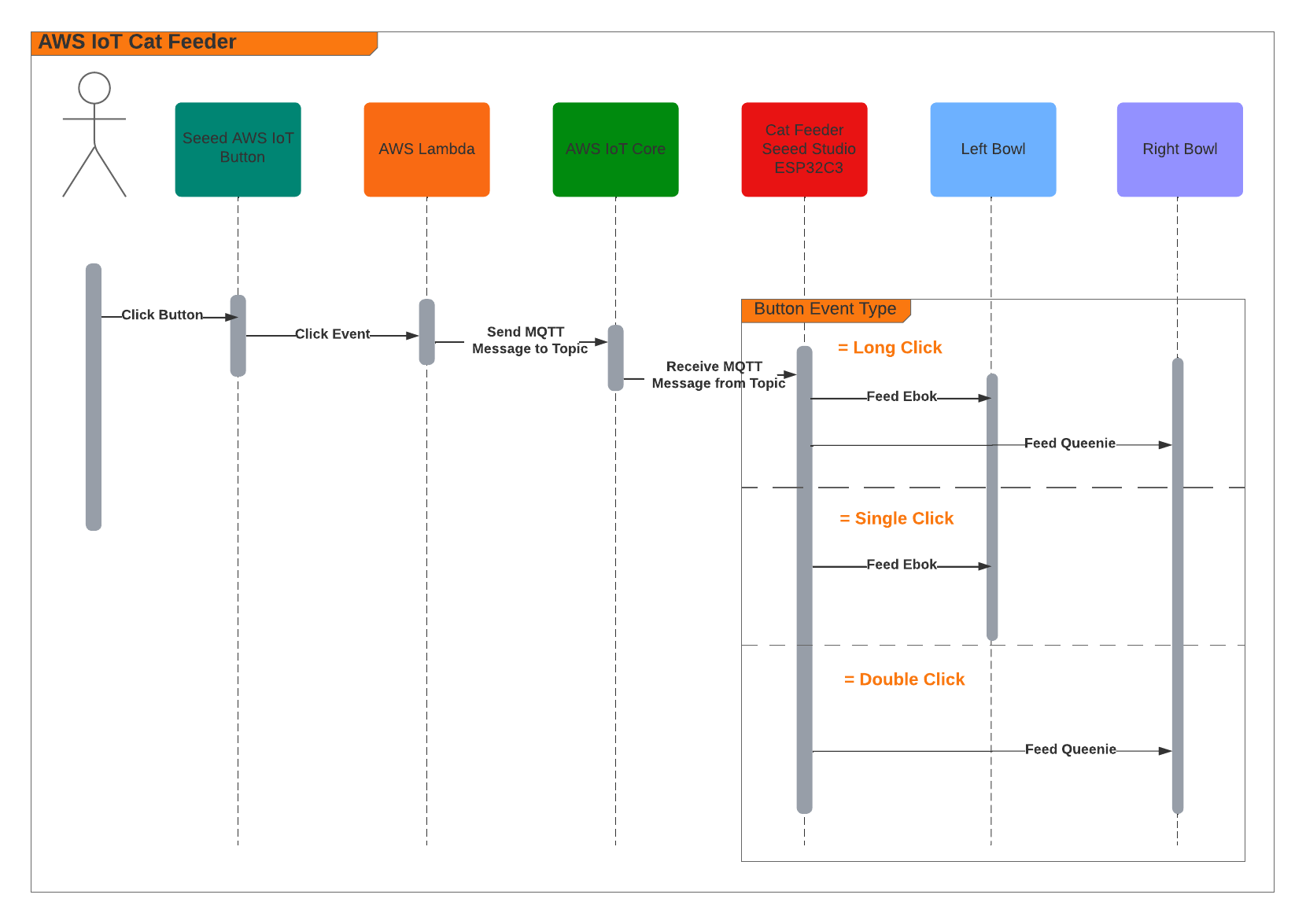
When the Feeder receives a MQTT message from the AWS IoT Core Service, it runs the motor for 10 seconds to dispense food into either one of food bowls, and if the message contains an event value to dispense food into both bowls we can run both motors concurrently using the L298N controller.
Here's a video of some timelapse picture captured during the 3 weeks it took to 3D print the feeder.
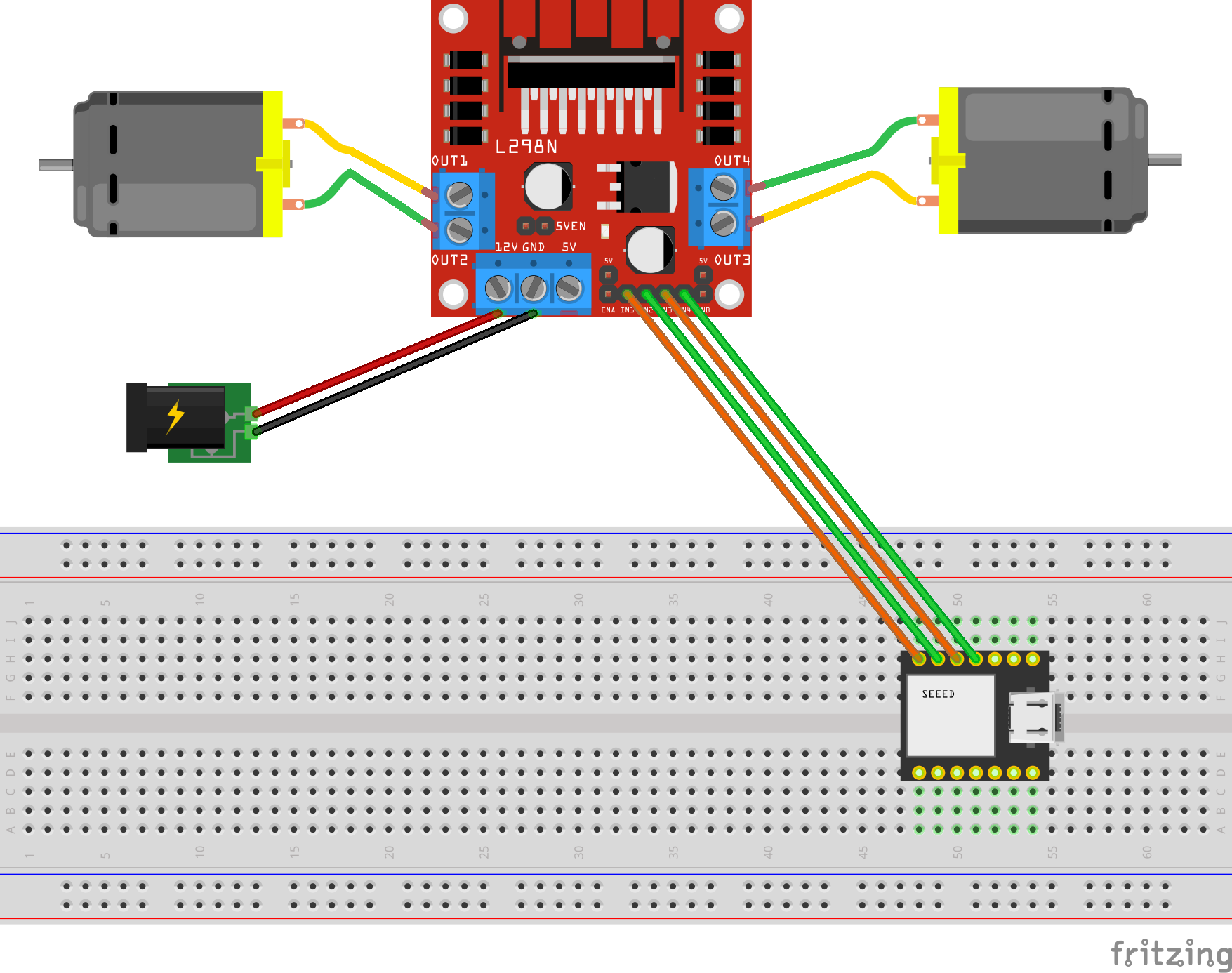
The Feeder is made up of a small handful of basic hardware components, below is a Breadboard diagram depicting the components used and how they are all wired up together. A regular 12V 2A DC power adapter supply is used to power all the components.
The code to start and stop a motor is about 10 lines of code as shown below. This is the completed version of the Arduino Sketch shown in Part 2 of this blog series when it was partially written at the time.
#include "secrets.h"
#include <WiFiClientSecure.h>
#include <MQTTClient.h>
#include <ArduinoJson.h>
#include "WiFi.h"
// The MQTT topics that this device should publish/subscribe
#define AWS_IOT_PUBLISH_TOPIC "cat-feeder/states"
#define AWS_IOT_SUBSCRIBE_TOPIC "cat-feeder/action"
WiFiClientSecure net = WiFiClientSecure();
MQTTClient client = MQTTClient(256);
int motor1pin1 = 32;
int motor1pin2 = 33;
int motor2pin1 = 16;
int motor2pin2 = 17;
void connectAWS()
{
WiFi.mode(WIFI_STA);
WiFi.begin(WIFI_SSID, WIFI_PASSWORD);
Serial.println("Connecting to Wi-Fi");
Serial.println(AWS_IOT_ENDPOINT);
while (WiFi.status() != WL_CONNECTED) {
delay(500);
Serial.print(".");
}
// Configure WiFiClientSecure to use the AWS IoT device credentials
net.setCACert(AWS_CERT_CA);
net.setCertificate(AWS_CERT_CRT);
net.setPrivateKey(AWS_CERT_PRIVATE);
// Connect to the MQTT broker on the AWS endpoint we defined earlier
client.begin(AWS_IOT_ENDPOINT, 8883, net);
// Create a message handler
client.onMessage(messageHandler);
Serial.println("Connecting to AWS IOT");
Serial.println(THINGNAME);
while (!client.connect(THINGNAME)) {
Serial.print(".");
delay(100);
}
if (!client.connected()) {
Serial.println("AWS IoT Timeout!");
return;
}
Serial.println("About to subscribe");
// Subscribe to a topic
client.subscribe(AWS_IOT_SUBSCRIBE_TOPIC);
Serial.println("AWS IoT Connected!");
}
void publishMessage()
{
StaticJsonDocument<200> doc;
doc["time"] = millis();
doc["state_1"] = millis();
doc["state_2"] = 2 * millis();
char jsonBuffer[512];
serializeJson(doc, jsonBuffer); // print to client
client.publish(AWS_IOT_PUBLISH_TOPIC, jsonBuffer);
Serial.println("publishMessage states to AWS IoT" );
}
void messageHandler(String &topic, String &payload) {
Serial.println("incoming: " + topic + " - " + payload);
StaticJsonDocument<200> doc;
deserializeJson(doc, payload);
const char* event = doc["event"];
Serial.println(event);
feedMe(event);
}
void setup() {
Serial.begin(9600);
connectAWS();
pinMode(motor1pin1, OUTPUT);
pinMode(motor1pin2, OUTPUT);
pinMode(motor2pin1, OUTPUT);
pinMode(motor2pin2, OUTPUT);
}
void feedMe(String event) {
Serial.println(event);
bool feedLeft = false;
bool feedRight = false;
if (event == "SINGLE") {
feedLeft = true;
}
if (event == "DOUBLE") {
feedRight = true;
}
if (event == "LONG") {
feedLeft = true;
feedRight = true;
}
if (feedLeft) {
Serial.println("run left");
digitalWrite(motor1pin1, HIGH);
digitalWrite(motor1pin2, LOW);
}
if (feedRight) {
Serial.println("run right");
digitalWrite(motor2pin1, HIGH);
digitalWrite(motor2pin2, LOW);
}
delay(10000);
digitalWrite(motor1pin1, LOW);
digitalWrite(motor1pin2, LOW);
digitalWrite(motor2pin1, LOW);
digitalWrite(motor2pin2, LOW);
delay(2000);
Serial.println("fed");
}
void loop() {
publishMessage();
client.loop();
delay(3000);
}
Demo Time
The Seeed AWS IoT Button is able to detect 3 different types of click events: Long, Single and Double, and we are able to leverage this all the way to the feeder so we will have it performing certains actions base on the click event type.
The video below demonstrates the following scenarios:
- Long Click: this will dispense food into both cat bowls
- Single Click: this will dispense food into Ebok's cat bowl
- Double Click: this will dispense food into Queenie's cat bowl
What's next?
Build the nervous system of an ultimate nerd project I have in mind that would allow me to voice control actions controlling servos, LEDs and audio outputs, by using a mesh of Seeed XIAO BLE Sense micro-controllers and TinyML Machine Learning.