FeedMyFurBabies – Using Custom Resources in AWS CDK to create AWS IoT Core Keys and Certificates

In a previous blog I talked about switching from CloudFormation template to AWS CDK as my preference for infrastructure as code, for provisioning my AWS Core IoT resources; I mentioned at the time whilst using resources using AWS CDK, as it would improve my productivity to focus on iterating and building. Although I switched to CDK for the reasons I described in my previous blog, there are some CloudFormation limitations that cannot be addressed just by switching to CDK alone.
In this blog I will talk about CloudFormation Custom Resources:
- What are CloudFormation Custom Resources?
- What is the problem I am trying to solve?
- How will I solve it?
- How am I using Custom Resources with AWS CDK?
CloudFormation Custom Resources allows you to write custom logic using AWS Lambda functions to provision resources, whether these resources live in AWS (you might ask why not just use CloudFormation or CDK: keep reading), on-premise or in other public clouds. These Custom Resource Lambda functions configured within a CloudFormation template, and are hooked into a CloudFormation Stack's lifecycle during the create, update and delete phases - to allow these lifecycle stages to happen, the logic must be implemented into the Lambda function's code.
What is the problem I am trying to solve?
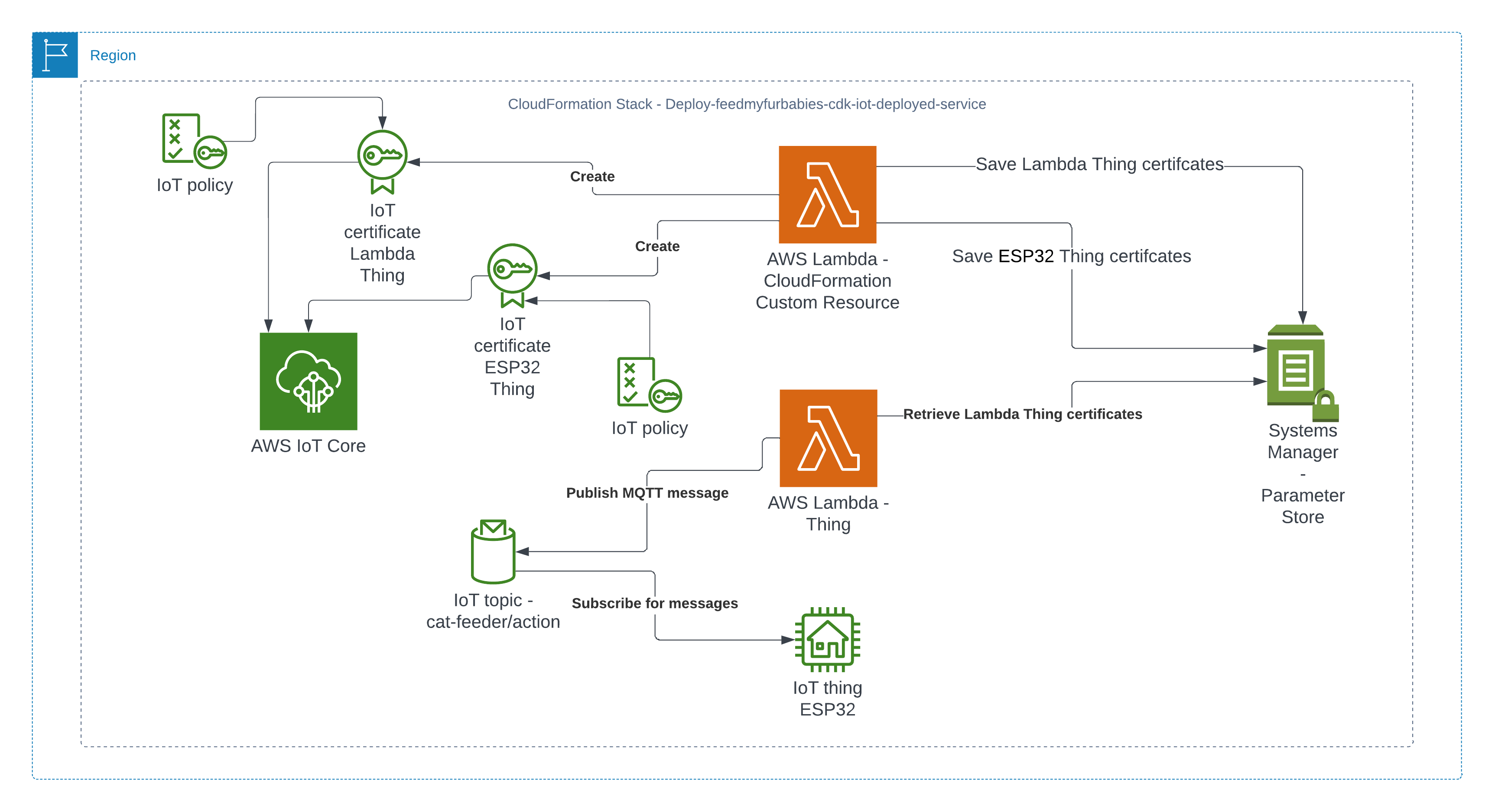
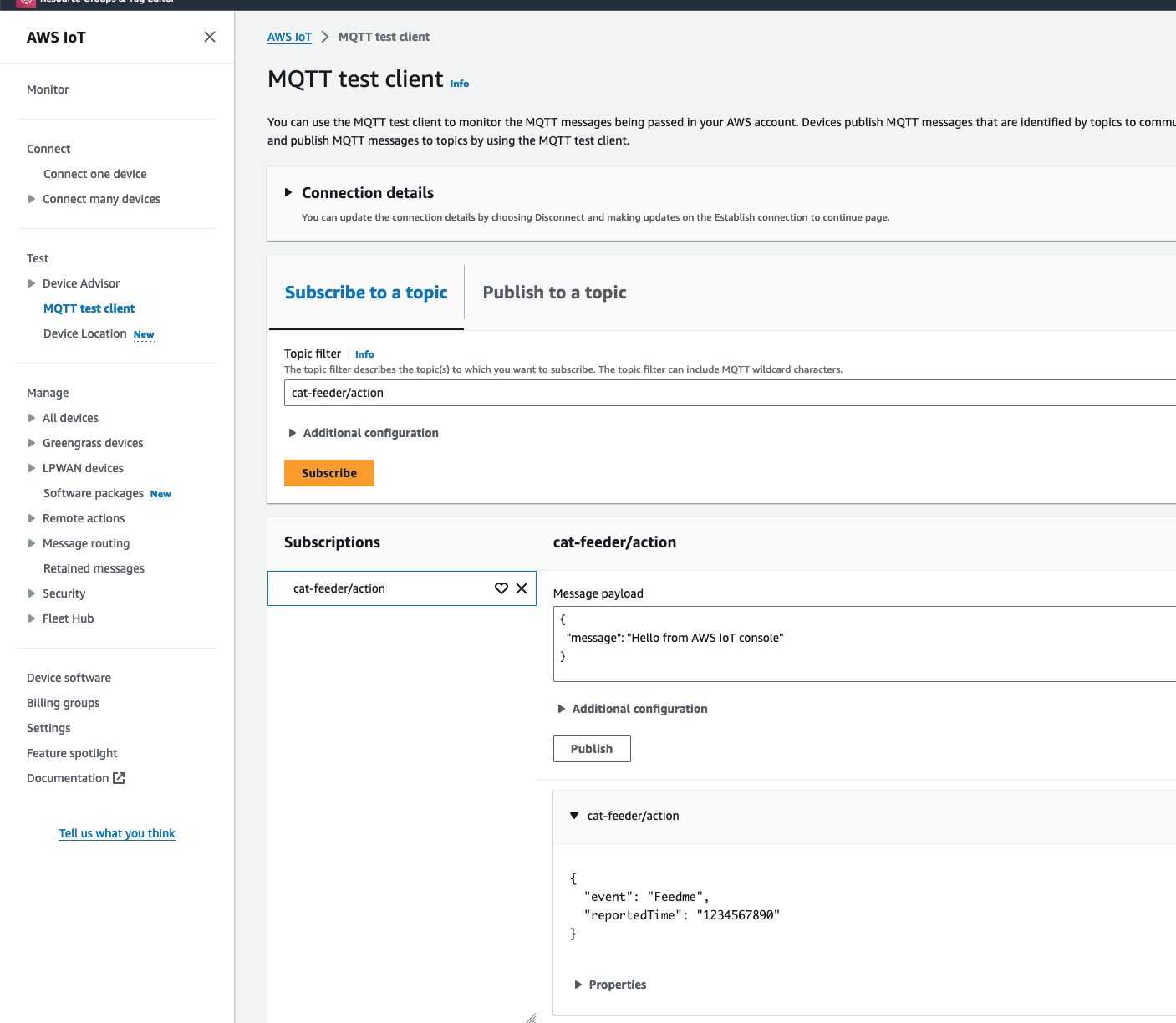
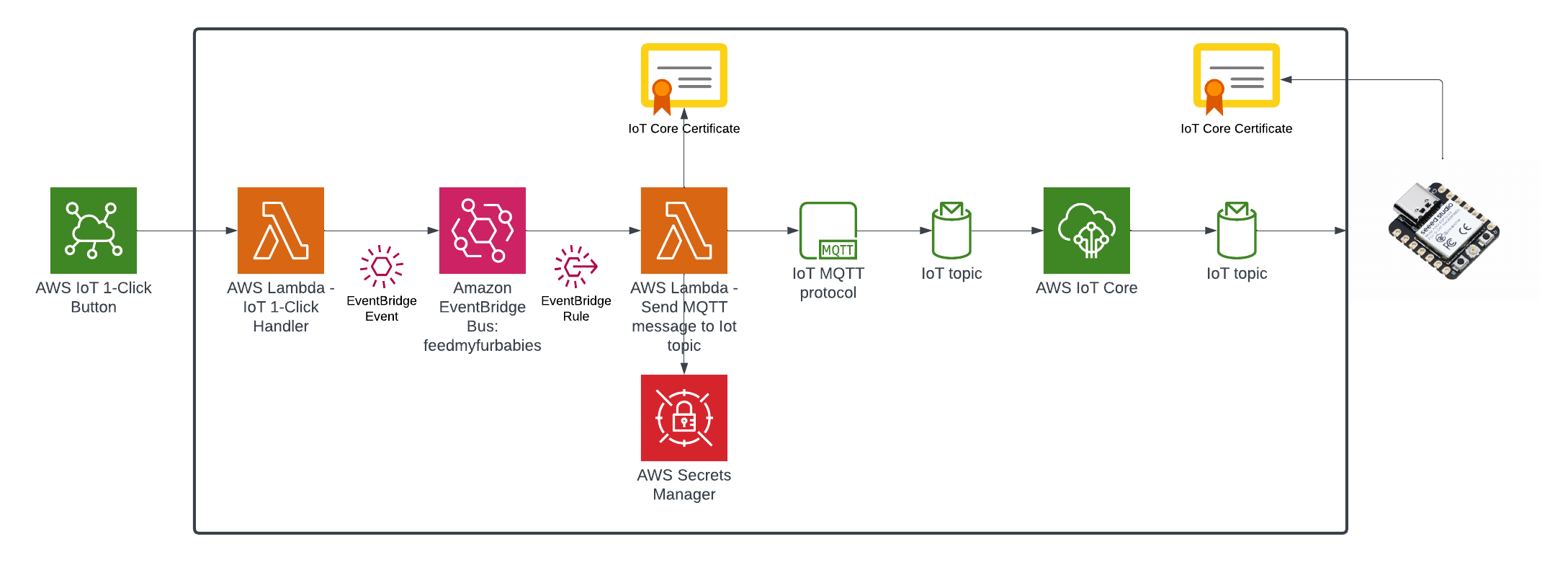
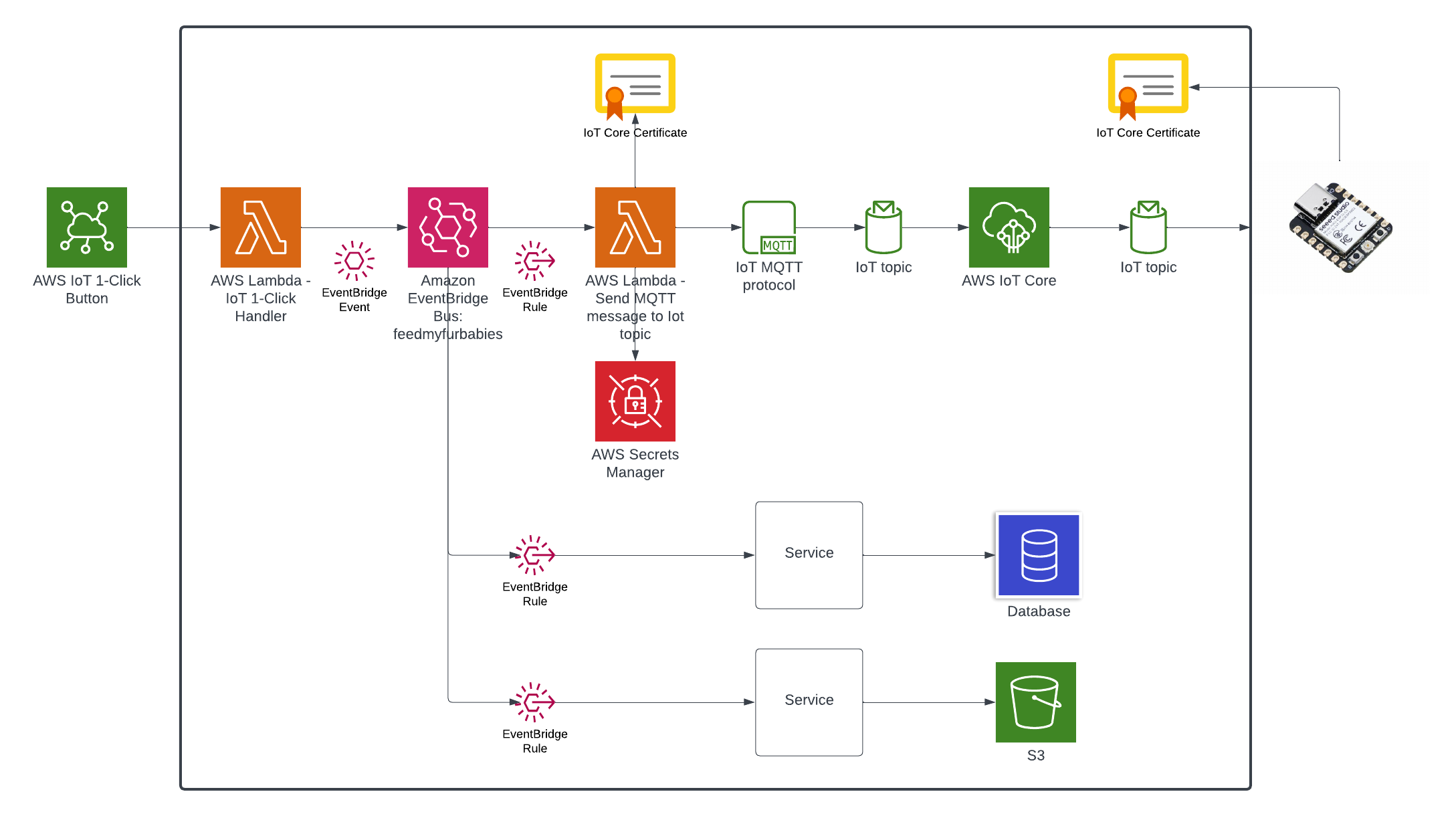
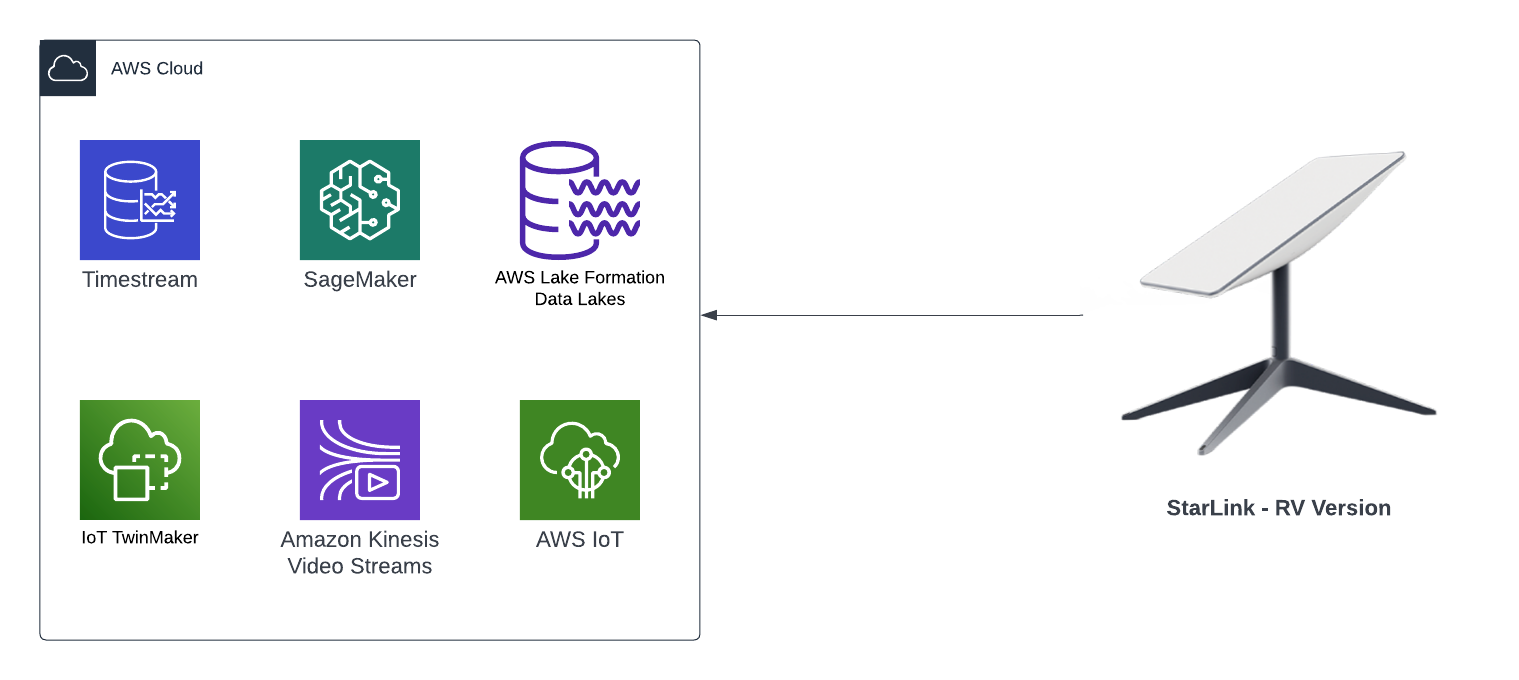
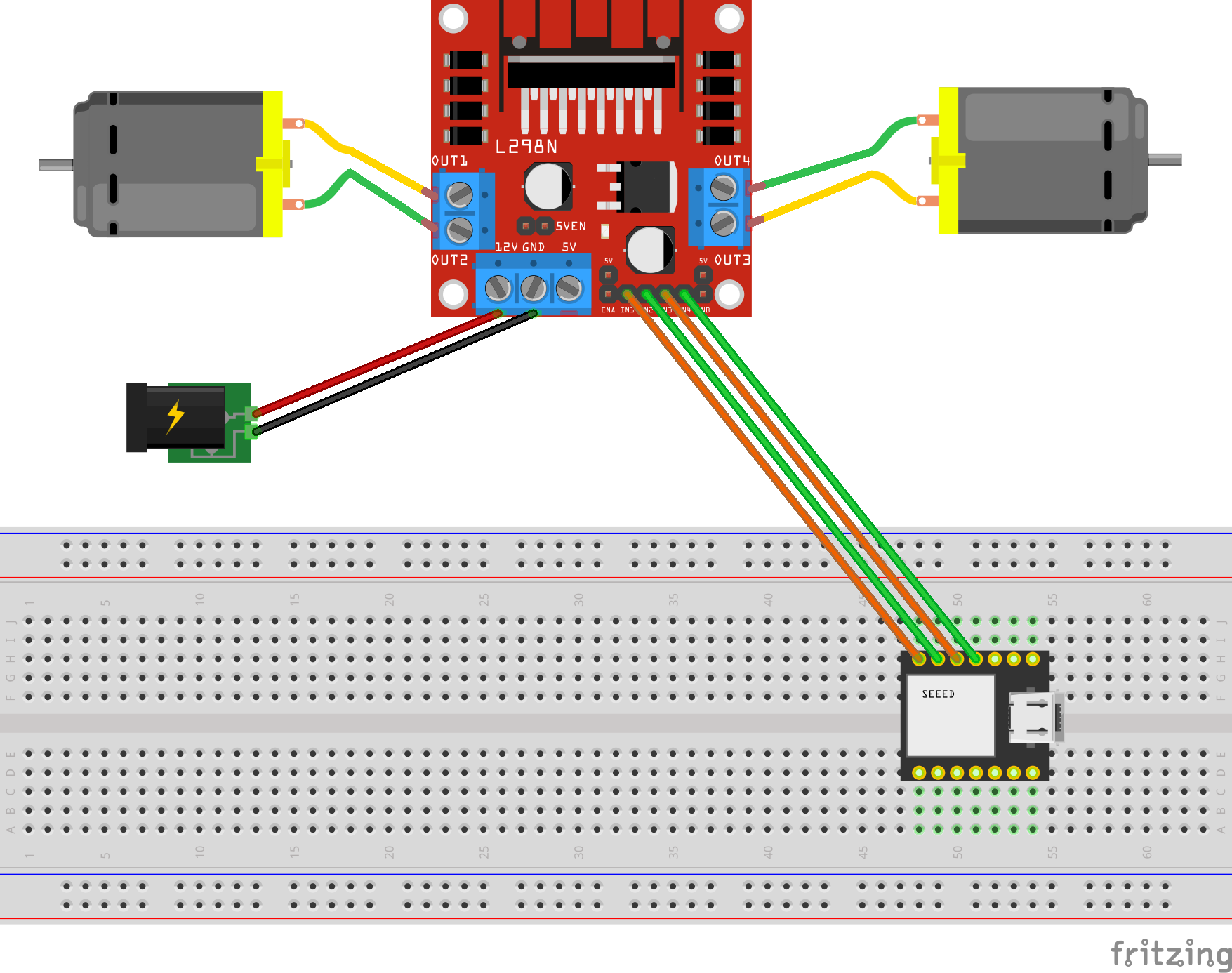
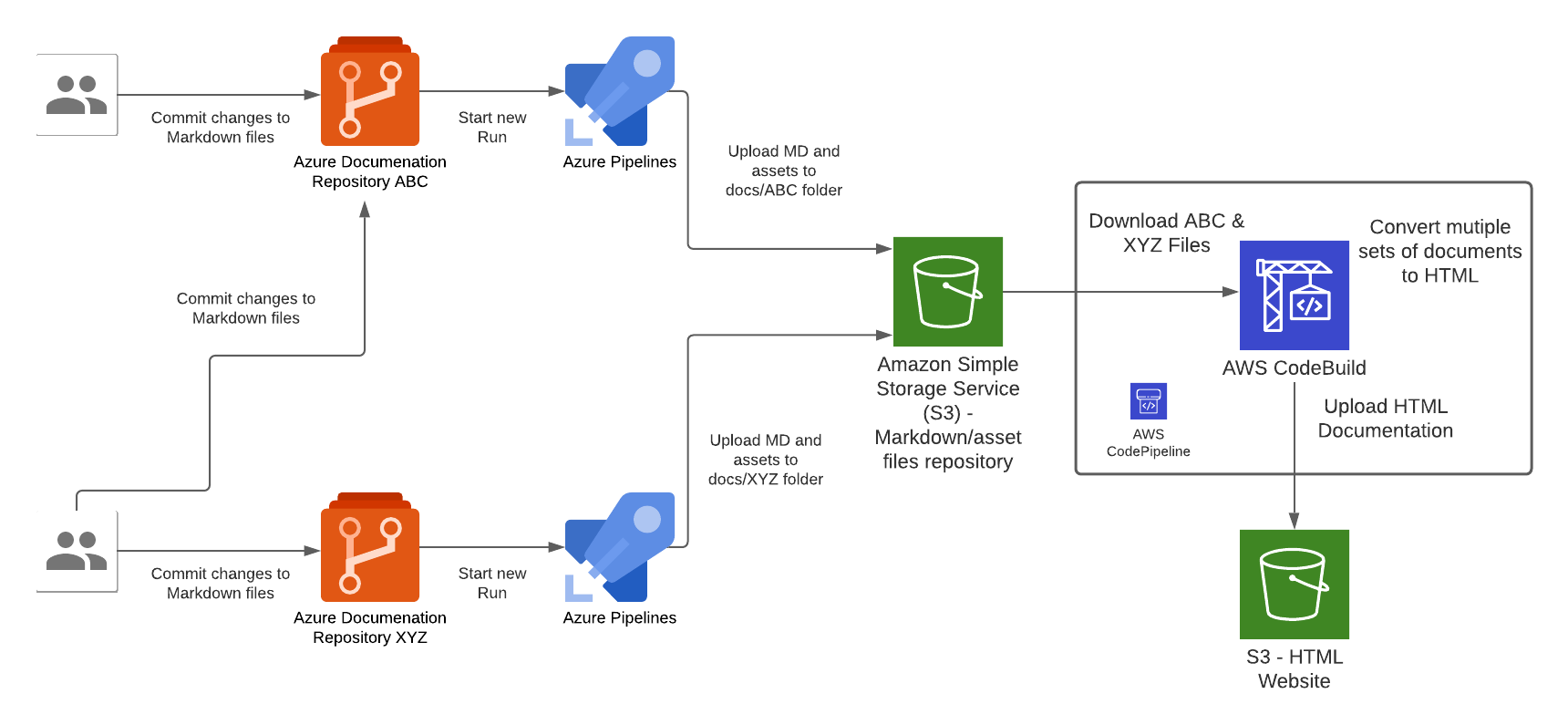
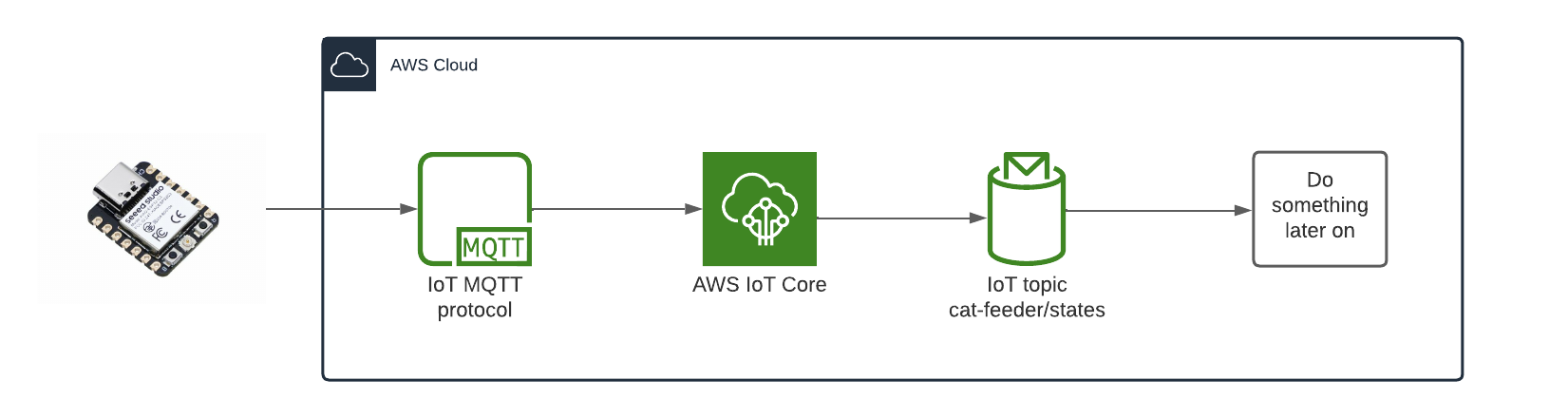
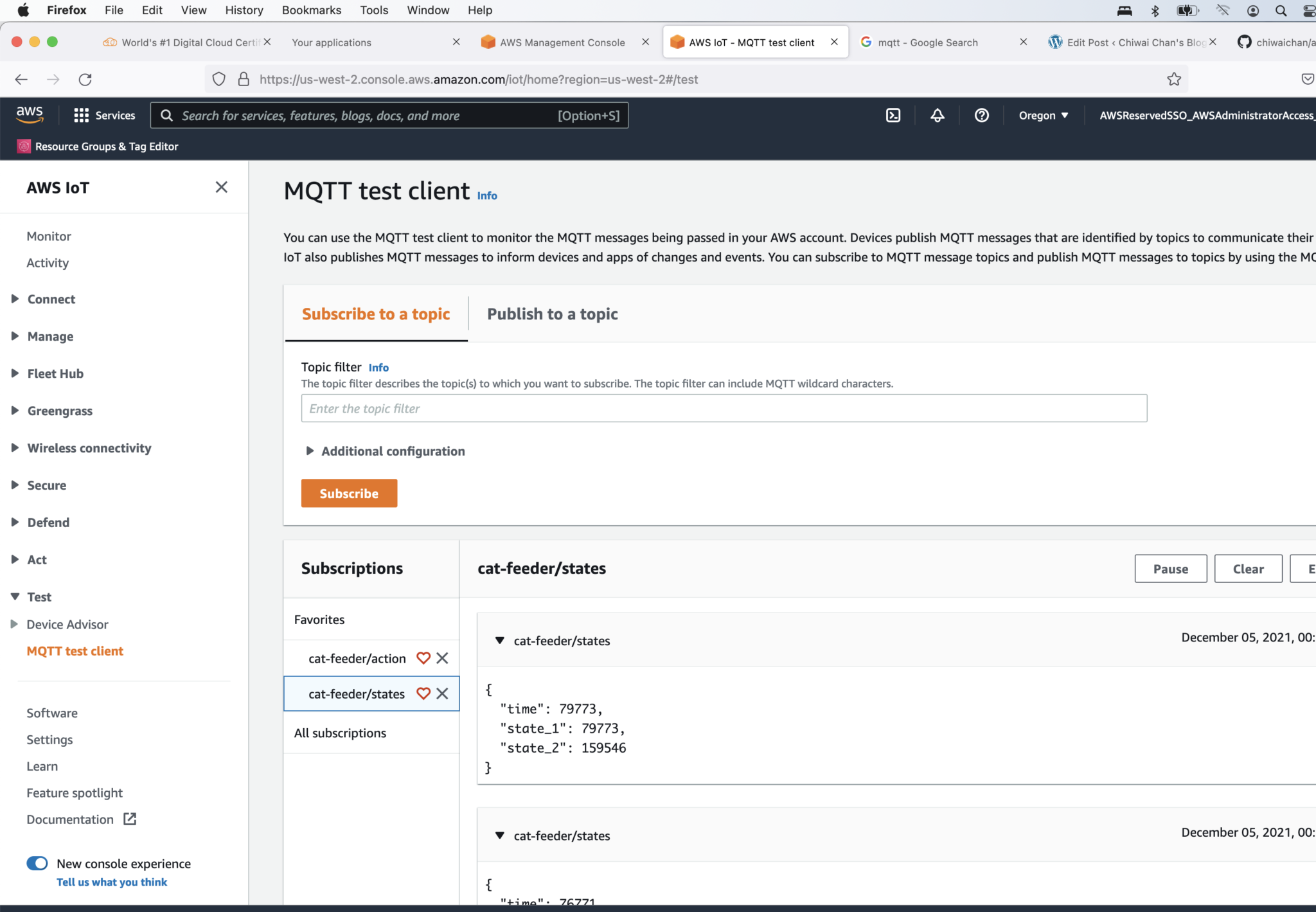
In my AWS IoT Core reference architecture, it relies on use of two sets of certificates and private keys; they are used to authenticate each Thing devices connecting to AWS IoT Core - this ensures that only trusted devices can establish a connection.
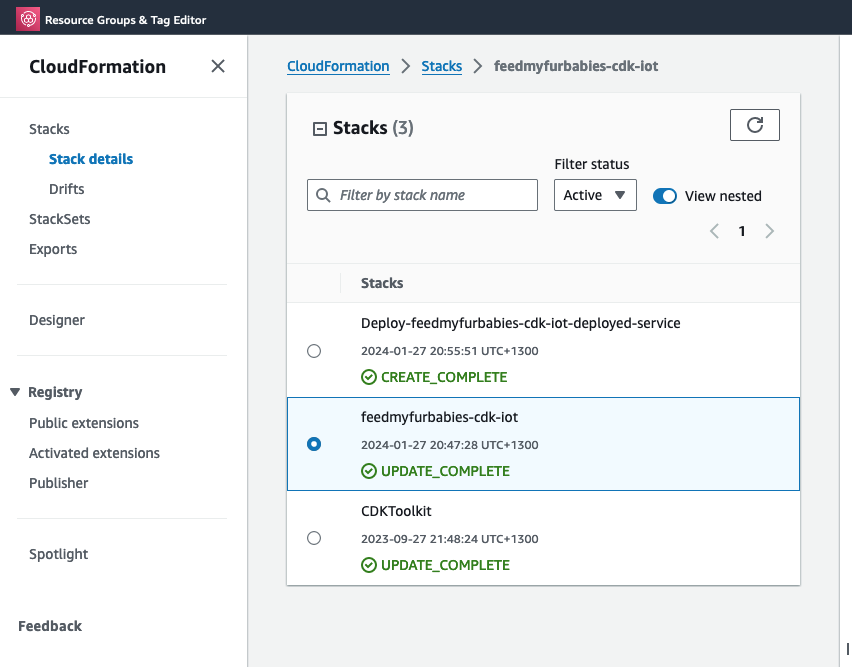
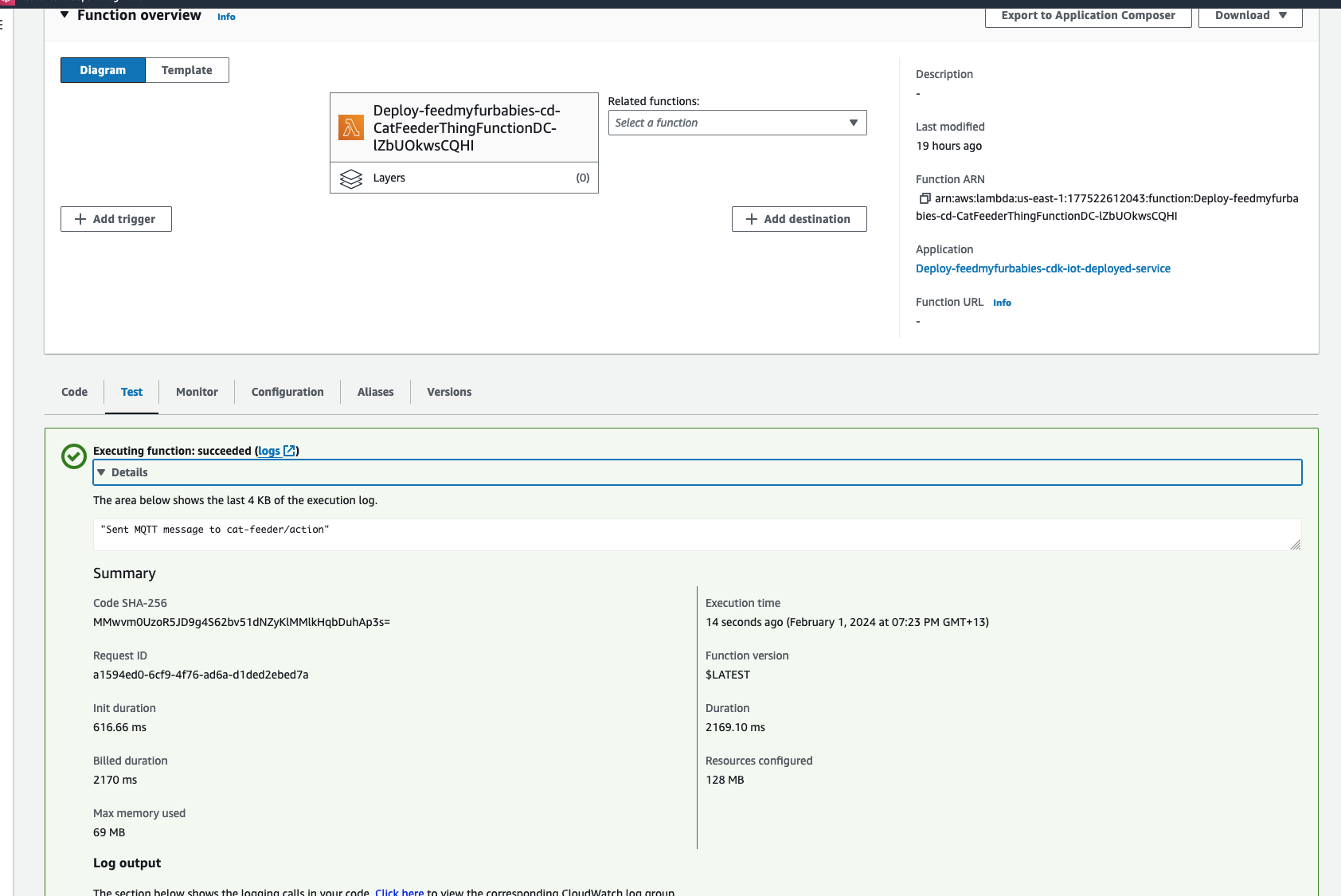
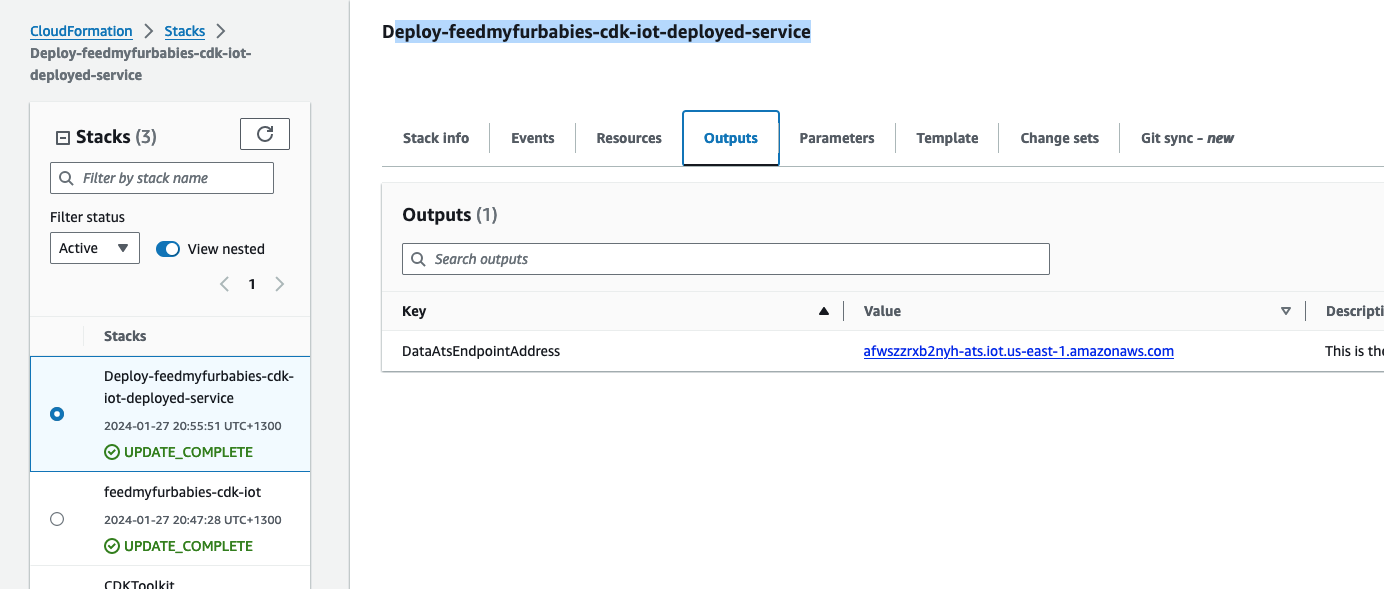
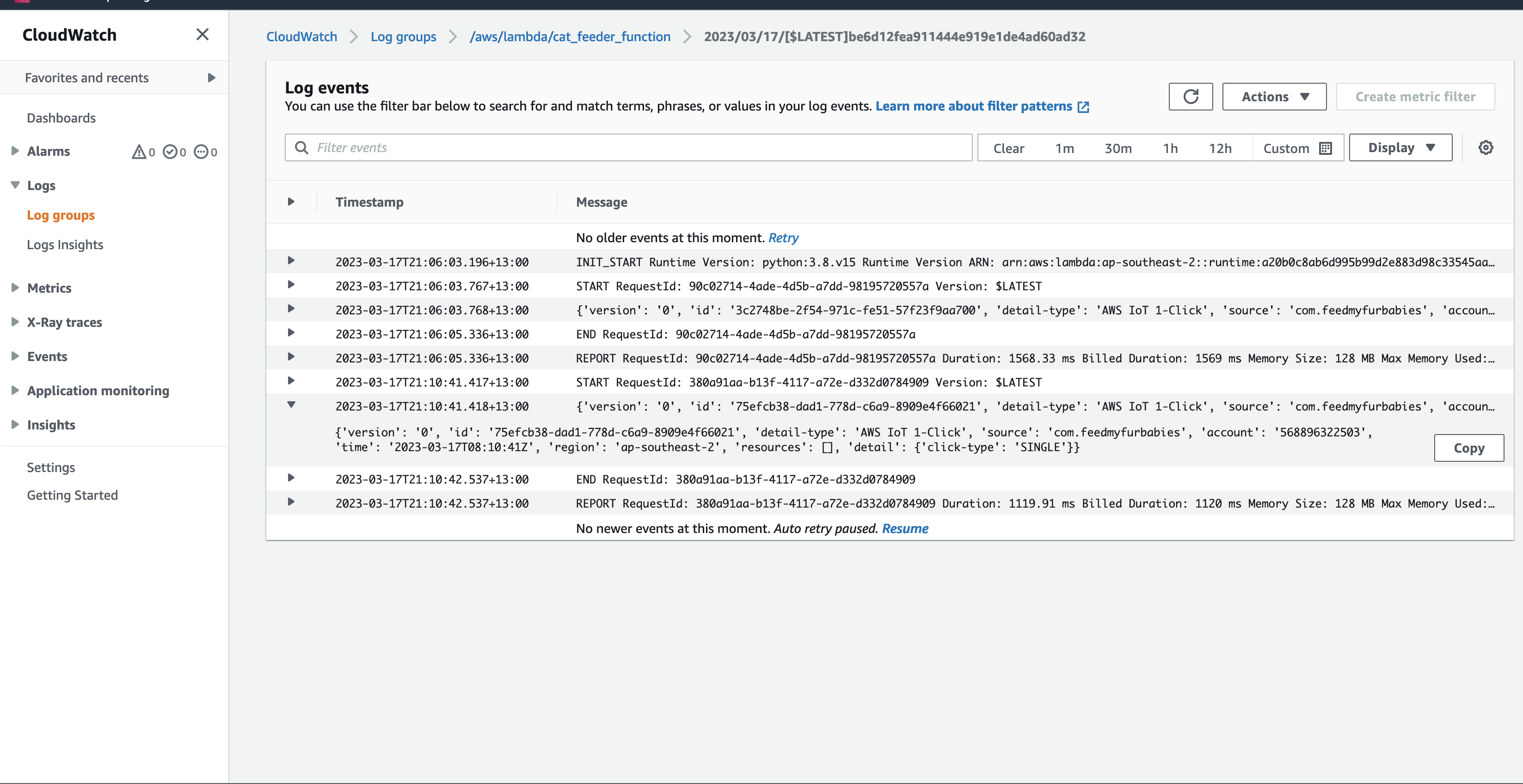
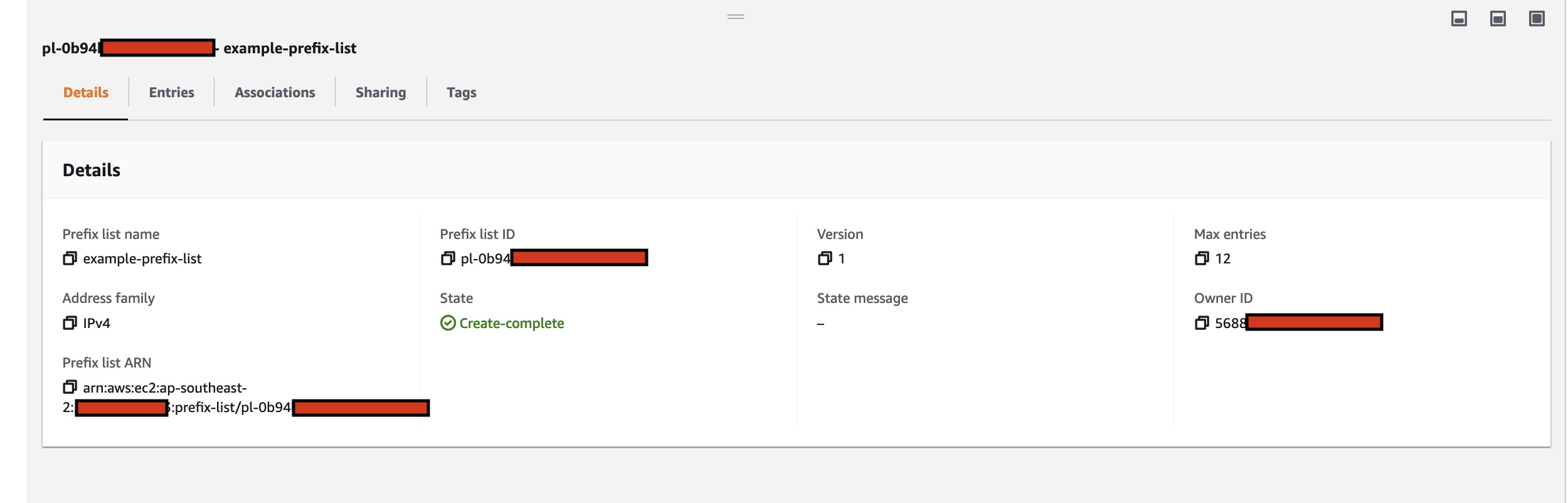
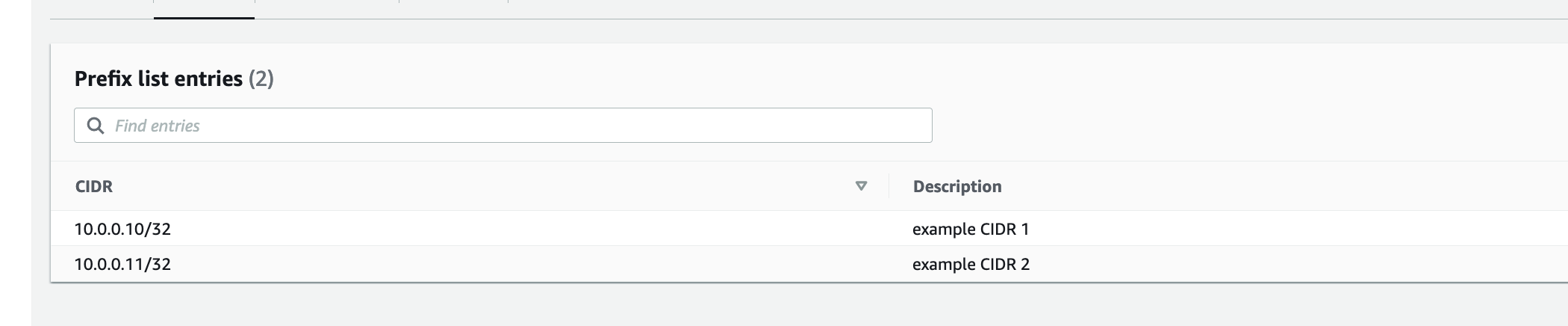
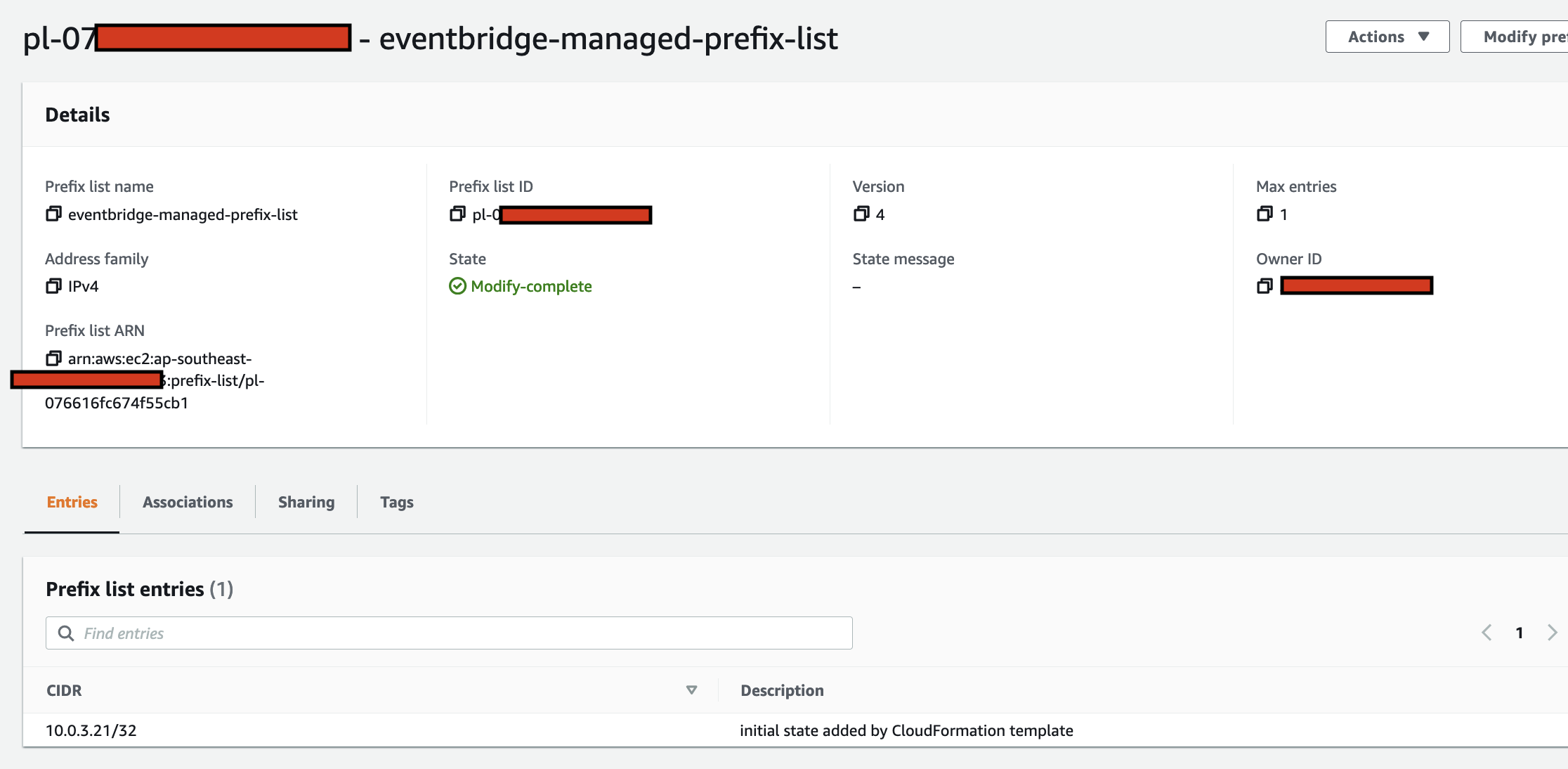
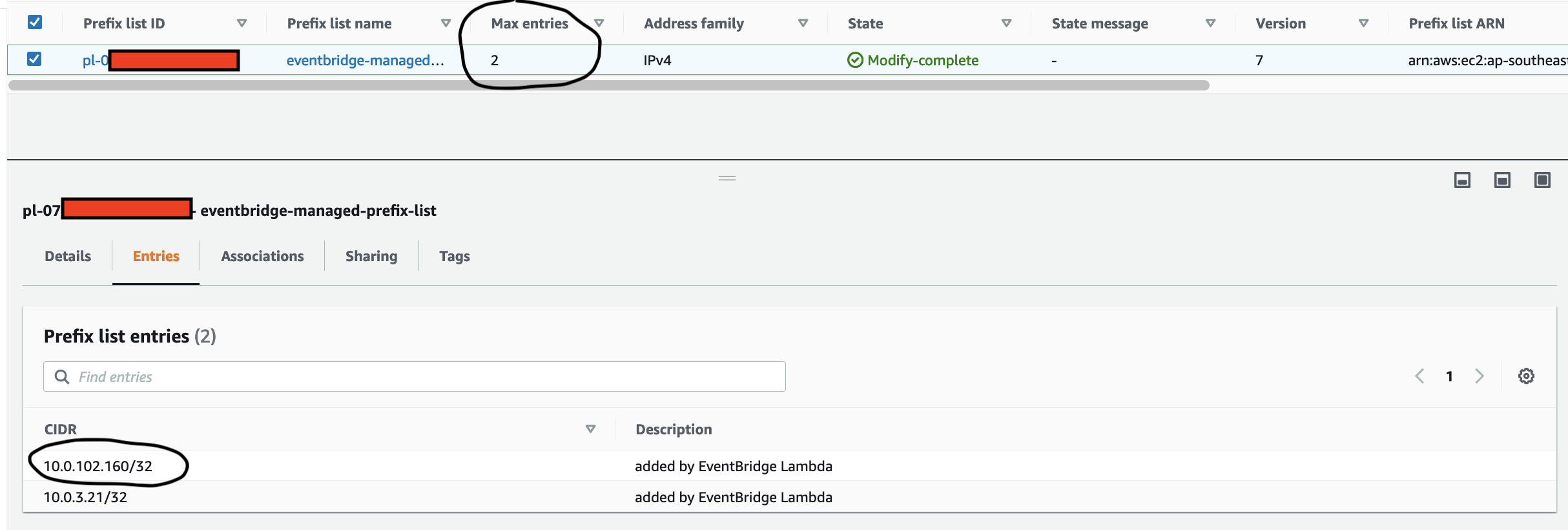
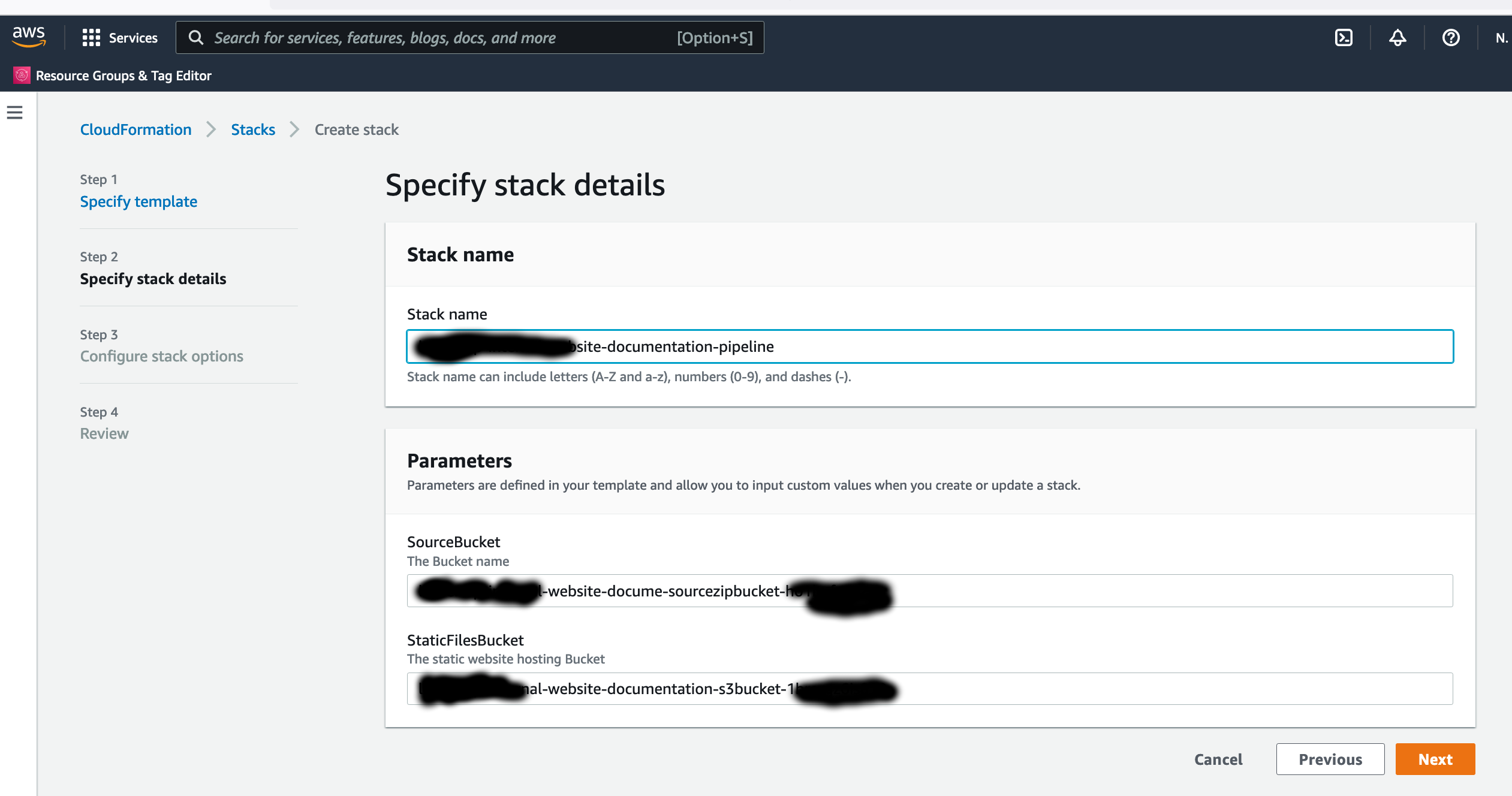
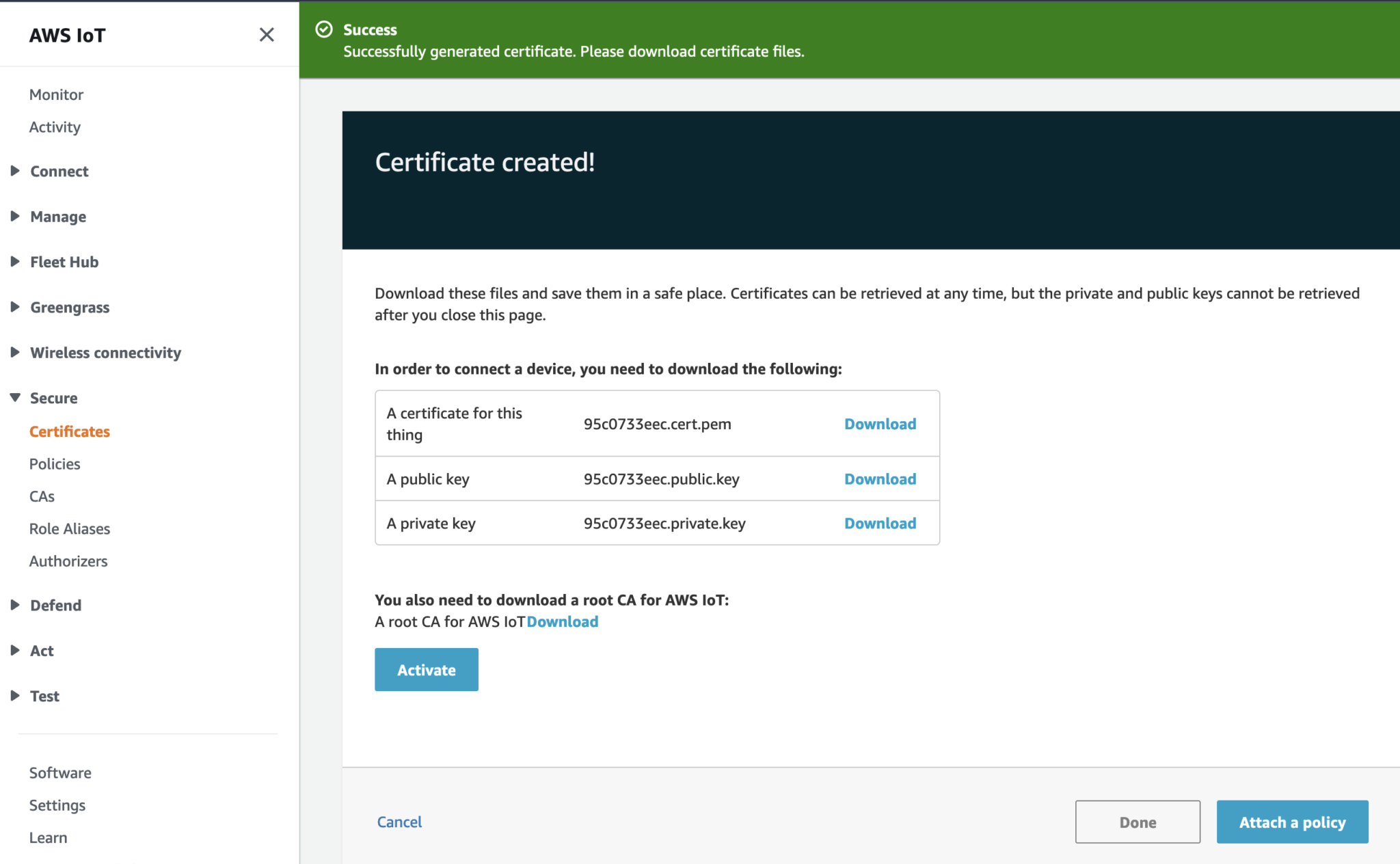
In the CloudFormation template version of my reference architecture, I had in the deployement instructions to manually create 2 Cetificates in the AWS Console for the IoT Core service, this is because CloudFormation doesn't directly support creation of certificates for AWS IoT Core; as shown in the screenshot below.
There is nothing wrong with creating the certificates manually within the AWS Console when you are trying out my example for the purpose of learning, but it would best to be able to deploy an entire set of resources using infrastructure as code, so we can achieve consistent repeatable deployments with as minimal effort as possible. If you are someone completely new to AWS, coding and IoT, my deployment instructions would be very overwheling and the chances of you successfully deploying a fully functional example will be very unlikely.
How will I solve it?
If you got this far and actually read what was written up to this point, you probably would have guess the solution is Custom Resources: so lets talk about how the problem described above was solved.
So we know Custom Resources is part of the solution, but one important thing we need to understand is that, even though there isn't the ability to create the certificates directly using CloudFormation, but there is support for creating the certificates using the AWS SDK Boto3 Python library: create_keys_and_certificate.
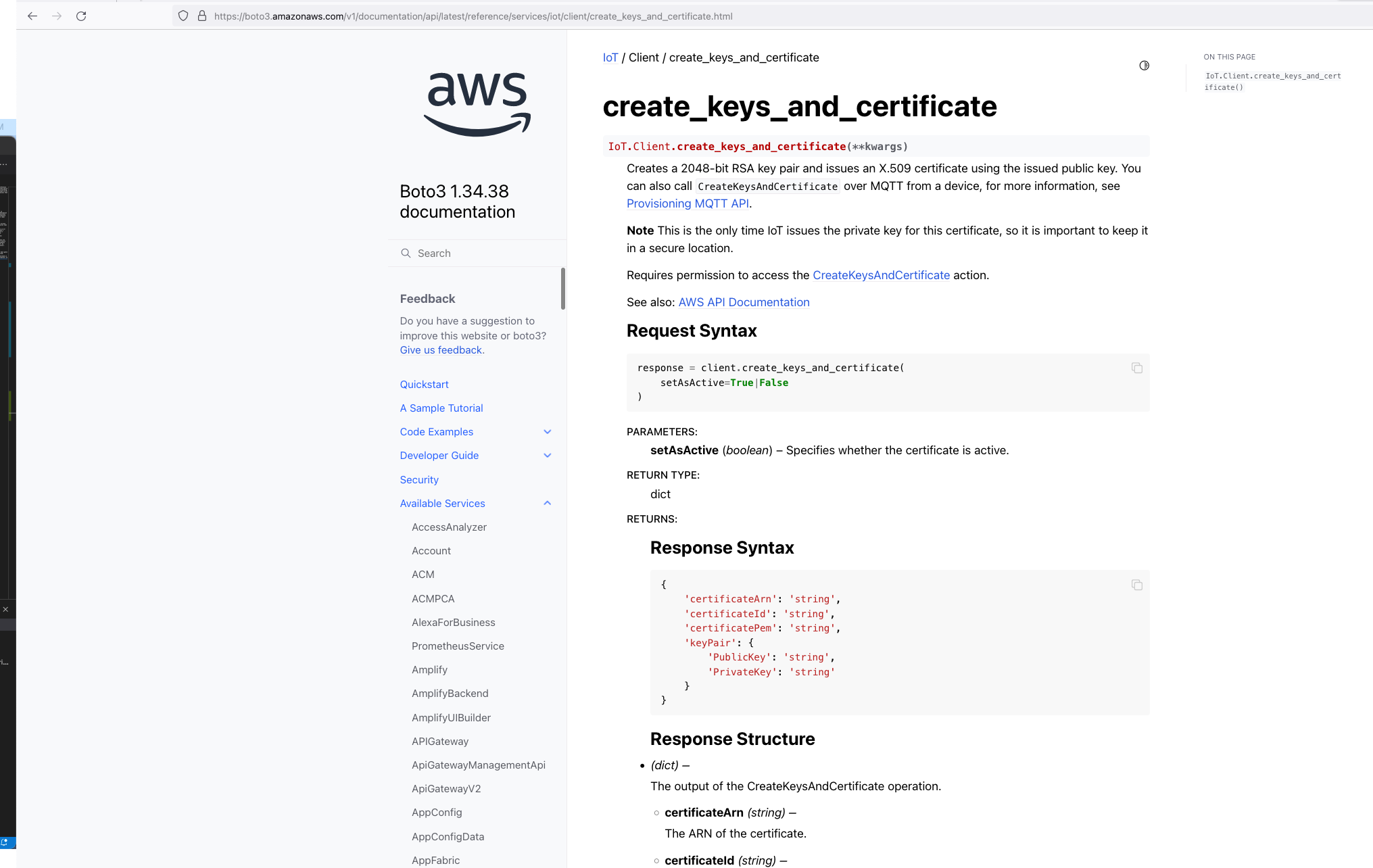
So essentially, we are able create the AWS IoT Core certificates using CloudFormation (in an indirectly way) but it requires the help of Custom Reources (a Lambda function) and the AWS Boto3 Python SDK.
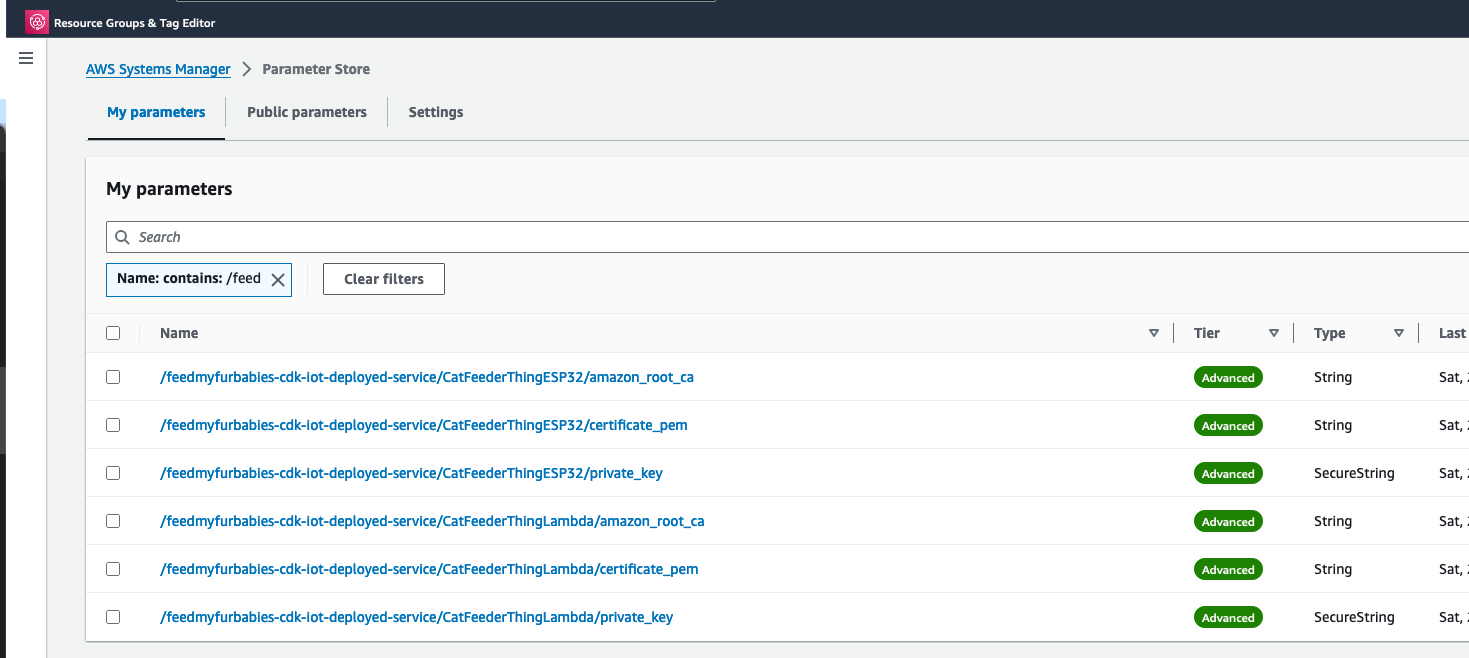
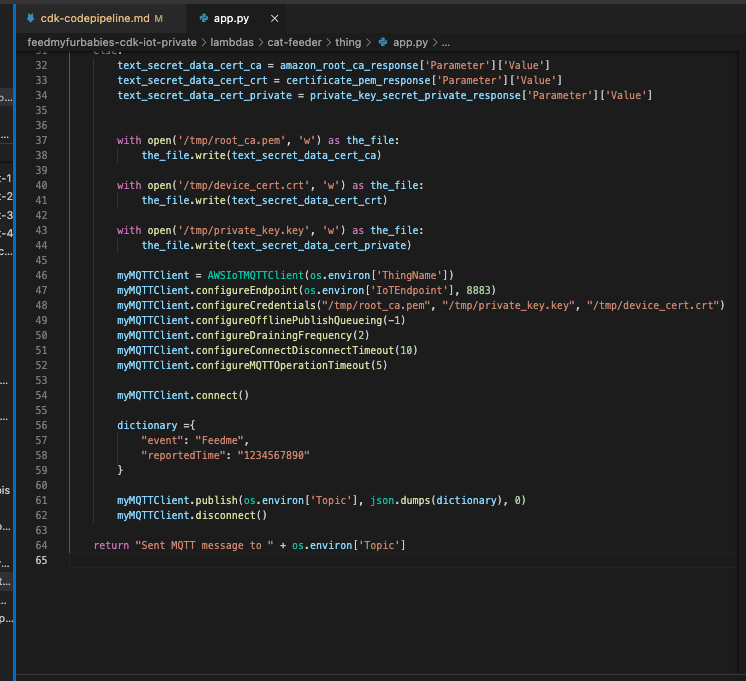
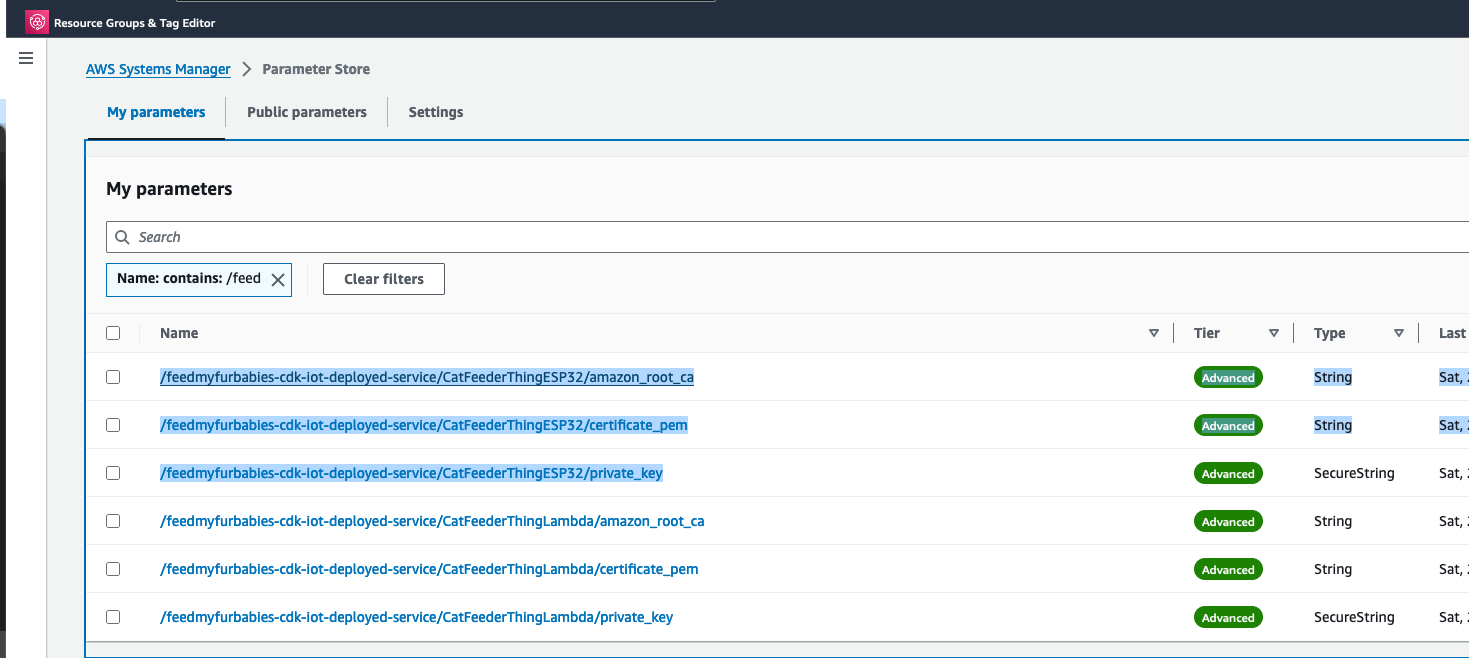
The Python code below is what I have in the Custom Resource Lambada function, it demonstrates the use of the Boto3 SDK to create the AWS IoT Core Certificates; and as a bonus, I am leveraging the Lambda function to save the Certificates into the AWS Systems Manager Parameter Store, this makes it much more simplier by centralising the Certificates in a single location without the engineer deploying this reference architecture having to manually copying/pasting/managing the Certificates - as I have forced readers in my original version of this reference architecture deployment. The code below also manages the lifecycle of the Certificates as the CloudFormation Stacks are deleted, by deleting the Certificates it created during the create phase of the lifecycle.
The overall flow to create the certificates is: Create a CloudFormation Stack --> Invoke the Custom Resource --> invoke the Boto3 IoT "create_keys_and_certificate" API --> save the certificates in Systems Manager Parameter Store
import os
import sys
import json
import logging as logger
import requests
import boto3
from botocore.config import Config
from botocore.exceptions import ClientError
import time
logger.getLogger().setLevel(logger.INFO)
def get_aws_client(name):
return boto3.client(
name,
config=Config(retries={"max_attempts": 10, "mode": "standard"}),
)
def create_resources(thing_name: str, stack_name: str, encryption_algo: str):
c_iot = get_aws_client("iot")
c_ssm = get_aws_client("ssm")
result = {}
# Download the Amazon Root CA file and save it to Systems Manager Parameter Store
url = "https://www.amazontrust.com/repository/AmazonRootCA1.pem"
response = requests.get(url)
if response.status_code == 200:
amazon_root_ca = response.text
else:
f"Failed to download Amazon Root CA file. Status code: {response.status_code}"
try:
# Create the keys and certificate for a thing and save them each as Systems Manager Parameter Store value later
response = c_iot.create_keys_and_certificate(setAsActive=True)
certificate_pem = response["certificatePem"]
private_key = response["keyPair"]["PrivateKey"]
result["CertificateArn"] = response["certificateArn"]
except ClientError as e:
logger.error(f"Error creating certificate, {e}")
sys.exit(1)
# store certificate and private key in SSM param store
try:
parameter_private_key = f"/{stack_name}/{thing_name}/private_key"
parameter_certificate_pem = f"/{stack_name}/{thing_name}/certificate_pem"
parameter_amazon_root_ca = f"/{stack_name}/{thing_name}/amazon_root_ca"
# Saving the private key in Systems Manager Parameter Store
response = c_ssm.put_parameter(
Name=parameter_private_key,
Description=f"Certificate private key for IoT thing {thing_name}",
Value=private_key,
Type="SecureString",
Tier="Advanced",
Overwrite=True
)
result["PrivateKeySecretParameter"] = parameter_private_key
# Saving the certificate pem in Systems Manager Parameter Store
response = c_ssm.put_parameter(
Name=parameter_certificate_pem,
Description=f"Certificate PEM for IoT thing {thing_name}",
Value=certificate_pem,
Type="String",
Tier="Advanced",
Overwrite=True
)
result["CertificatePemParameter"] = parameter_certificate_pem
# Saving the Amazon Root CA in Systems Manager Parameter Store,
# Although this file is publically available to download, it is intended to provide a complete set of files to try out this working example with as much ease as possible
response = c_ssm.put_parameter(
Name=parameter_amazon_root_ca,
Description=f"Amazon Root CA for IoT thing {thing_name}",
Value=amazon_root_ca,
Type="String",
Tier="Advanced",
Overwrite=True
)
result["AmazonRootCAParameter"] = parameter_amazon_root_ca
except ClientError as e:
logger.error(f"Error creating secure string parameters, {e}")
sys.exit(1)
try:
response = c_iot.describe_endpoint(endpointType="iot:Data-ATS")
result["DataAtsEndpointAddress"] = response["endpointAddress"]
except ClientError as e:
logger.error(f"Could not obtain iot:Data-ATS endpoint, {e}")
result["DataAtsEndpointAddress"] = "stack_error: see log files"
return result
# Delete the resources created for a thing when the CloudFormation Stack is deleted
def delete_resources(thing_name: str, certificate_arn: str, stack_name: str):
c_iot = get_aws_client("iot")
c_ssm = get_aws_client("ssm")
try:
# Delete all the Systems Manager Parameter Store values created to store a thing's certificate files
parameter_private_key = f"/{stack_name}/{thing_name}/private_key"
parameter_certificate_pem = f"/{stack_name}/{thing_name}/certificate_pem"
parameter_amazon_root_ca = f"/{stack_name}/{thing_name}/amazon_root_ca"
c_ssm.delete_parameters(Names=[parameter_private_key, parameter_certificate_pem, parameter_amazon_root_ca])
except ClientError as e:
logger.error(f"Unable to delete parameter store values, {e}")
try:
# Clean up the certificate by firstly revoking it then followed by deleting it
c_iot.update_certificate(certificateId=certificate_arn.split("/")[-1], newStatus="REVOKED")
c_iot.delete_certificate(certificateId=certificate_arn.split("/")[-1])
except ClientError as e:
logger.error(f"Unable to delete certificate {certificate_arn}, {e}")
def handler(event, context):
props = event["ResourceProperties"]
physical_resource_id = ""
try:
# Check if this is a Create and we're failing Creates
if event["RequestType"] == "Create" and event["ResourceProperties"].get(
"FailCreate", False
):
raise RuntimeError("Create failure requested, logging")
elif event["RequestType"] == "Create":
logger.info("Request CREATE")
resp_lambda = create_resources(
thing_name=props["CatFeederThingLambdaCertName"],
stack_name=props["StackName"],
encryption_algo=props["EncryptionAlgorithm"]
)
resp_controller = create_resources(
thing_name=props["CatFeederThingControllerCertName"],
stack_name=props["StackName"],
encryption_algo=props["EncryptionAlgorithm"]
)
# The values in the response_data could be used in the CDK code, for example used as Outputs for the CloudFormation Stack deployed
response_data = {
"CertificateArnLambda": resp_lambda["CertificateArn"],
"PrivateKeySecretParameterLambda": resp_lambda["PrivateKeySecretParameter"],
"CertificatePemParameterLambda": resp_lambda["CertificatePemParameter"],
"AmazonRootCAParameterLambda": resp_lambda["AmazonRootCAParameter"],
"CertificateArnController": resp_controller["CertificateArn"],
"PrivateKeySecretParameterController": resp_controller["PrivateKeySecretParameter"],
"CertificatePemParameterController": resp_controller["CertificatePemParameter"],
"AmazonRootCAParameterController": resp_controller["AmazonRootCAParameter"],
"DataAtsEndpointAddress": resp_lambda[
"DataAtsEndpointAddress"
],
}
# Using the ARNs of the pairs of certificates created as the PhysicalResourceId used by Custom Resource
physical_resource_id = response_data["CertificateArnLambda"] + "," + response_data["CertificateArnController"]
elif event["RequestType"] == "Update":
logger.info("Request UPDATE")
response_data = {}
physical_resource_id = event["PhysicalResourceId"]
elif event["RequestType"] == "Delete":
logger.info("Request DELETE")
certificate_arns = event["PhysicalResourceId"]
certificate_arns_array = certificate_arns.split(",")
resp_lambda = delete_resources(
thing_name=props["CatFeederThingLambdaCertName"],
certificate_arn=certificate_arns_array[0],
stack_name=props["StackName"],
)
resp_controller = delete_resources(
thing_name=props["CatFeederThingControllerCertName"],
certificate_arn=certificate_arns_array[1],
stack_name=props["StackName"],
)
response_data = {}
physical_resource_id = certificate_arns
else:
logger.info("Should not get here in normal cases - could be REPLACE")
send_cfn_response(event, context, "SUCCESS", response_data, physical_resource_id)
except Exception as e:
logger.exception(e)
sys.exit(1)
def send_cfn_response(event, context, response_status, response_data, physical_resource_id):
response_body = json.dumps({
"Status": response_status,
"Reason": "See the details in CloudWatch Log Stream: " + context.log_stream_name,
"PhysicalResourceId": physical_resource_id,
"StackId": event['StackId'],
"RequestId": event['RequestId'],
"LogicalResourceId": event['LogicalResourceId'],
"Data": response_data
})
headers = {
'content-type': '',
'content-length': str(len(response_body))
}
requests.put(event['ResponseURL'], data=response_body, headers=headers)
How I am using Custom Resources with AWS CDK?
What I am about to describe in this section can also be applied to a regular CloudFormation template, as a matter of fact, CDK will generate a CloudFormation template behind the scenes during the Synth phase of the CDK code in the latest version of my IoT Core reference architecture implemented using AWS CDK: https://chiwaichan.co.nz/blog/2024/02/02/feedmyfurbabies-i-am-switching-to-aws-cdk/
If you want to get straight into deploying the CDK version of reference architecture, go here: https://github.com/chiwaichan/feedmyfurbabies-cdk-iot
In my CDK code, I provision the Custom Resource lambda function and the associated IAM Roles and Polices using the Python code below. The line of code "code=lambda_.Code.from_asset("lambdas/custom-resources/iot")" loads the Custom Resource Lambda function code shown earlier.
# IAM Role for Lambda Function
custom_resource_lambda_role = iam.Role(
self, "CustomResourceExecutionRole",
assumed_by=iam.ServicePrincipal("lambda.amazonaws.com")
)
# IAM Policies
iot_policy = iam.PolicyStatement(
actions=[
"iot:CreateCertificateFromCsr",
"iot:CreateKeysAndCertificate",
"iot:DescribeEndpoint",
"iot:AttachPolicy",
"iot:DetachPolicy",
"iot:UpdateCertificate",
"iot:DeleteCertificate"
],
resources=["*"] # Modify this to restrict to specific secrets
)
# IAM Policies
ssm_policy = iam.PolicyStatement(
actions=[
"ssm:PutParameter",
"ssm:DeleteParameters"
],
resources=[f"arn:aws:ssm:{self.region}:{self.account}:parameter/*"] # Modify this to restrict to specific secrets
)
logging_policy = iam.PolicyStatement(
actions=[
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
resources=["arn:aws:logs:*:*:*"]
)
custom_resource_lambda_role.add_to_policy(iot_policy)
custom_resource_lambda_role.add_to_policy(ssm_policy)
custom_resource_lambda_role.add_to_policy(logging_policy)
# Define the Lambda function
custom_lambda = lambda_.Function(
self, 'CustomResourceLambdaIoT',
runtime=lambda_.Runtime.PYTHON_3_8,
handler="app.handler",
code=lambda_.Code.from_asset("lambdas/custom-resources/iot"),
timeout=Duration.seconds(60),
role=custom_resource_lambda_role
)
# Properties to pass to the custom resource
custom_resource_props = {
"EncryptionAlgorithm": "ECC",
"CatFeederThingLambdaCertName": f"{cat_feeder_thing_lambda_name.value_as_string}",
"CatFeederThingControllerCertName": f"{cat_feeder_thing_controller_name.value_as_string}",
"StackName": f"{construct_id}",
}
# Create the Custom Resource
custom_resource = CustomResource(
self, 'CustomResourceIoT',
service_token=custom_lambda.function_arn,
properties=custom_resource_props
)
When you execute a "cdk deploy" using the CLI on the CDK reference architecture, CDK will synthesize from the Python CDK code, a CloudFormation template, and then create a CloudFormation Stack using the synthesized CloudFormation template for you.
For more details on the CDK AWS IoT reference architecture and deployment instructions, please visit my blog: https://chiwaichan.co.nz/blog/2024/02/02/feedmyfurbabies-i-am-switching-to-aws-cdk/