4×4 fun with a bit of Iot, vlogging and Machine Learning – Part 1


Months prior to the very first lockdown I had gotten myself on the waitlist for a 4x4 Jimny, so I could take it to the beach without worrying about getting beached like I likely would in a regular front wheel drive hatchback; or take it to the bushes to climb some hills and see how far I would get without flipping it (badly). Knowing I wouldn't be able to drive it for an long indefinitely amount time so I decided to cancel the order back then; in some ways I was sad then but in many ways I am happy now that I have had a fair amount of time to have a good think about what else I could do with the Jimny whilst taking it on these adventures.
The time spent mulling has lead to another new blog series; this will take on a similar build approach I took while building my Iot Cat Feeder, but this time it will be on a larger scale in terms of the amount of moving parts and components; also, I would get to enjoy myself this time instead of the cats. For those that are unfamiliar with the approach I took in my prior build, I will start the blog series by proposing an idea I have in mind with a certainty of about 70% of achieving a functional prototype - this is mainly due to not having the background nor experience on most of the skills required to build out this idea.
Generally, I would create a new Part for the Blog Series as I achieve a milestone during the build, where I talk about what was achieved in the milestone and provide the details on how I got there; where possible I would include a public Github repository for any code written for the build.
So enough of my rumbling.
What is it that I am wanting to build?
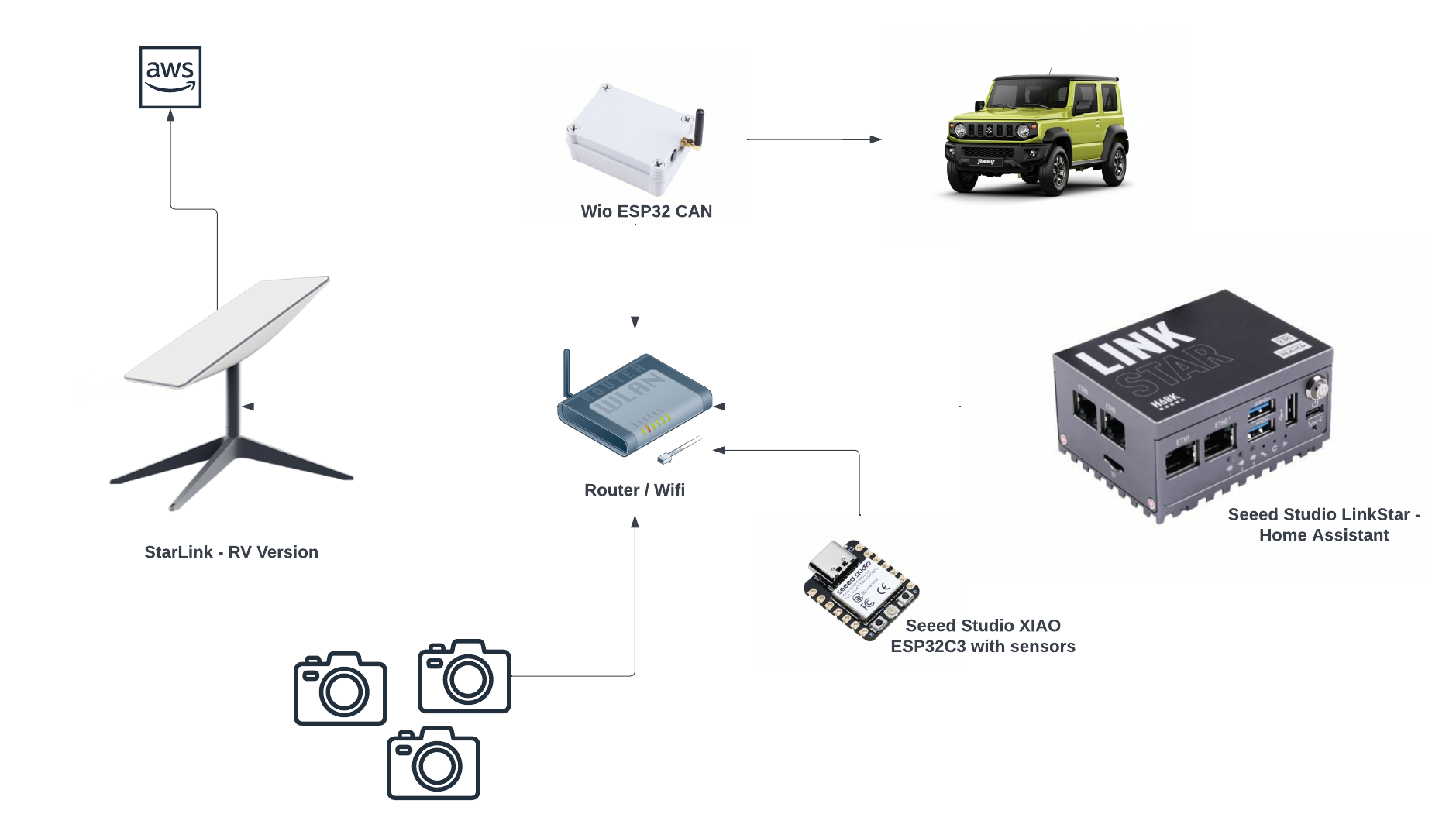
As you may have already predicted what is involved in this build from the image above, yes it will involve a 4x4 - I have a Jimny on the way; and some cloud buzz words like Iot and Machine Learning.
The goals of this build is to:
- Develop a solution to capture video recordings of my 4x4 adventures of the entire journey with 5+ viewpoints around the vehicle in 4K resolution, realistically I might only be about to capture full HD videos as explained further down this blog.
- Capture and store the vehicle's telemetries at regular intervals as the vehicle is driven using the CAN Bus protocol, e.g. speed, RPM of the engine and any other states the car is in.
- Capture other useful data not monitored by the vehicle's CAN Bus, such as GPS co-ordinates and the environment where the vehicle is at during the time - e.g. temperature, humidity, luminosity and many more using hand picked sensors.
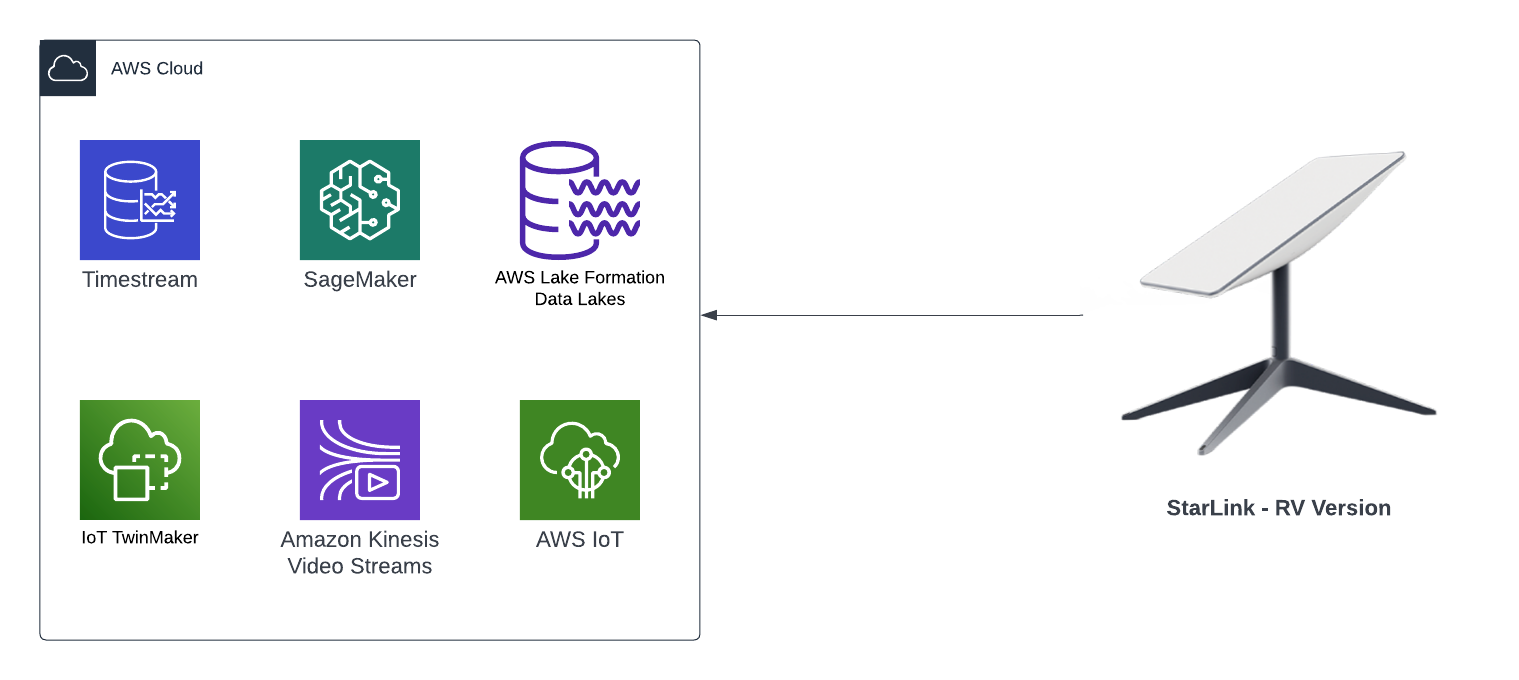
- Ingest in real time all the videos, CAN Bus and sensor data captured into an AWS Datalake
If I were able to achieve all the goals in the list above, then I would like to also achieve these goals:
- Create a Digital Twin using AWS TwinMaker of the Jimny and associate all the sensors and devices captured with it
- Train Machine Learning models using the data ingest in the AWS Datalake
- Do something with the AWS Deeplens sitting in my draw for the past year with the ML models created above, perhaps warn me I am able to do something that will cause the Jimny to land on its roof like last time by making predictions on an ML model.
- Have some sort of cloud solution that spits out a video for each of my trips so I can use it to upload to YouTube, with the video displaying some of the telemetries and sensor data captured.
At the end of the blog series I will conclude whether I was able build something that was functional, and whether or not I was able to achieve all the goals I have stated in the 2 lists above.
Where I am in terms of progress for this build?
It has been a bit of a challenge to source certain types of electronic components at the moment as some may already know, so I've only managed to source the majority of components required at this point in time.
So far I have source the following components:
Starlink RV version

I had been wanting one of these for a long time so when I saw it on special I jumped on it straight away. This is the RV version so it means it can be taken anywhere with me, so I will mount this on a roof rack - one reason why I do not want to have the Jimny on its roof because it would not be fun to be somewhere with no internet for a long period of time.

The ideal location to place the Starlink is in a spot with no obstruction and as far away from everything as possible, however, when I tested it out in my tiny back yard with it sitting in the center surrounded by 2 houses (both 2 stories) and a high fence, I got the following results:
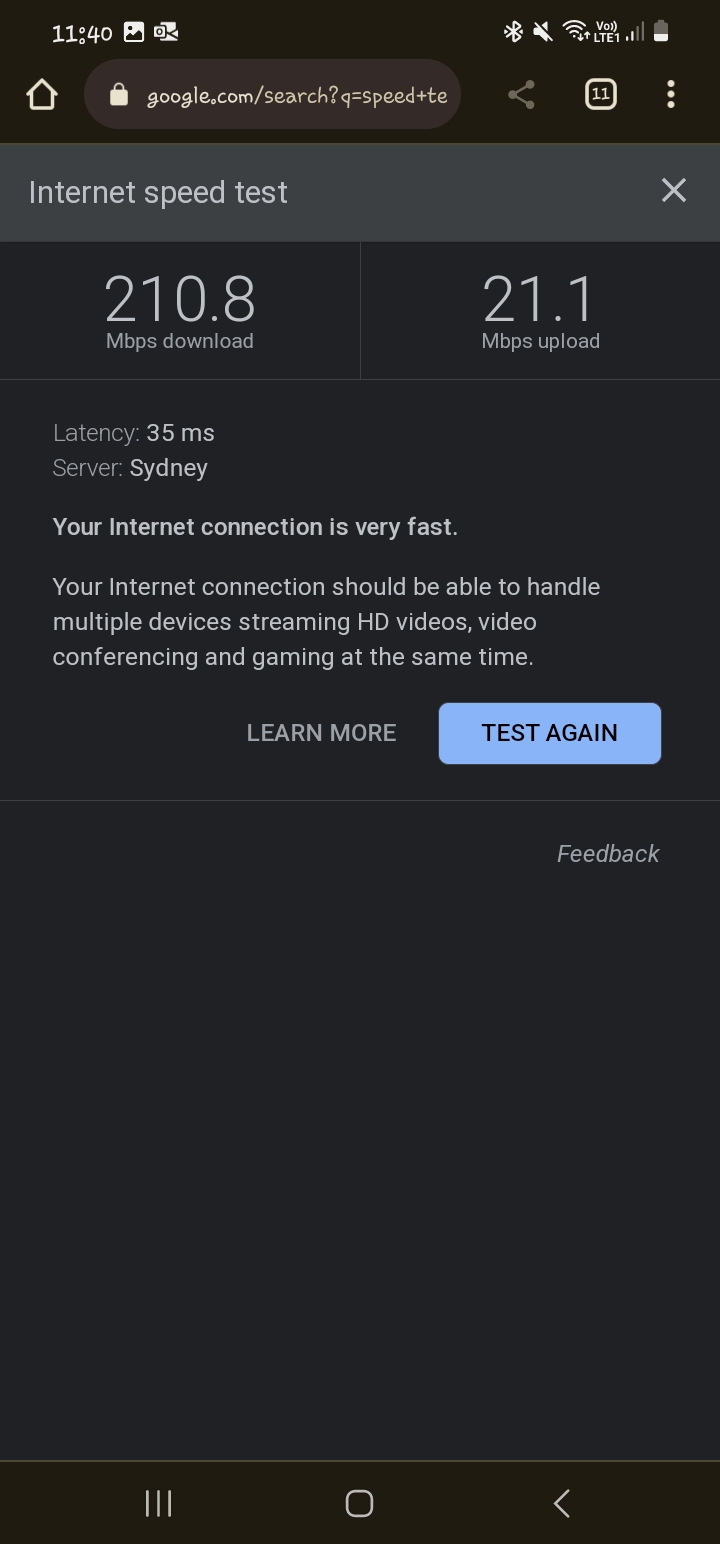
Although the speed is as fast as you get on the one of the slowest fibre plan available in New Zealand, the upload speed is the ultimate factor that determines how many live feeds we can ingest into the Datalake; a 4K resolution video is 20Mbps so that does not leave much bandwidth for all of the other data types, results may be better depending on where I am at the time, and also, unless Starlink offers symmetrical upload speeds then we are forced with full HD feeds, FYI download speeds can be as high as 500Mbps in some parts of the world. One option is to store the data onto a NAS drive via the Home Assistant installed on the LinkStar - a device similar to a Raspberry PI, then upload the videos into the Datalake after I get home - I like to avoid this as it is too much admin.
Router / Wifi
Got a few lying around at house doing nothing.
Cameras
I also have some spare cameras to use; the feed on these can be served using the RTSP protocol, I also have a few ESP32-CAMs I recently purchased so this build will use a combination of the 2 camera types. Most webcams can be used for this.
Seeed Studio XIAO ESP32C3
I have a bunch of these as they are my go tos when I build projects using micro-controllers; they are like $5 USD: Seeed Studio XIAO ESP32C3, one of, if not the smallest ESP32s I've come across and is more reliable than other ones I've used previously.

I also have various sensors for use that measures:
- Distance from objects
- Temperature
- Sound
- Humidity
- Luminosity
- CO2
Seeed Studio LinkStar with Home Assistant

I'll be using this to pull the feeds from the cameras, as well as saving the videos onto a NAS if we go down that route.
What is left to source?
- Seeed Studio WIO ESP32 CAN - this is a kit I'll be using to interface with the CAN Bus to retrieve telemetries from the Jimny.
- Jimny
Next blog
The next blog in this series I will take all the components I currently have and link it all up and detail what and how I got there.
